The state of HTTP clients, or why you should use httpx
15 Oct 2023TL;DR most http clients you’ve been using since the ruby heyday are either broken, unmaintained, or stale, and you should be using httpx nowadays.
Every year, a few articles come out with a title similar to “the best ruby http clients of the year of our lord 20xx”. Most of the community dismisses them as clickbait, either because of the reputation of the content owner website, companies pushing their developers to write meaningless content in their company tech blog for marketing purposes, or AI bots trained on similar articles from the previous decade and serving you the same contet over and over.
And they’re right. Most of the times, these articles are hollow, devoid of meaningful examples or discussions about relevant features, trade-offs or performance characteristics, and mostly rely on shallow popularity metrics such as total downloads, number of stars on GitHub, or number of twitter followers from the core maintainer, to justify selections. They’ll repeat what you know already for years: faraday is downloaded 20 million times a year, httparty parties hard, no one likes net-http, and there are too many http clients in the ruby community.
These articles very rarely mention newcomers. Being the developer of httpx, a relatively recent (created in 2017) HTTP client, and having extensively researched the competition, I can’t help but feel that there’s a lot that hasn’t been mentioned yet. So, given the context I gathered all over these years, I believe I can myself do the article I’d like someone else to have done already about the topic but didn’t.
Alas, this is yet another “the state of ruby HTTP clients in 2023”. There are many like it, but this one is mine. And while you’ll find it hardly surprising that I recommend you to use httpx nowadays (I’m the maintainer after all), I’ll try to make the analysis as unbiased as possible, and play the devil’s advocate here and there.
Population
As of the time of writing this article, there are 33 http client gems listed in ruby toolbox. It takes a book to cover them all! How can I limit the sample to relevant gems only? What classifies as “relevant” anyway?
While the ruby toolbox ranking suffers from the “social” factor as well (github and number of stars are an important metric in their score calculation after all), it does collect data around maintenance health, which is a variable to take into account.
Categorization is not very precise either; for instance, some of the listed gems are hardly HTTP “clients”, rather a layer built on top of other HTTP clients instead. For instance, flexirest or restfulie are DSLs around “RESTful API” concepts; hyperclient is a DSL to build HAL JSON API clients; json_api_client does the same for APIs following the JSON API Spec; all of them are using net-http, ruby’s own standard library include HTTP client, under the hood though. So one can dismiss them as not really HTTP clients.
Some of the listed gems can’t event perform HTTP requests. For instance, multipart-post, the second best-ranked by project score index, is essentially a group of components to be used with net-http to enable generation of multipart requests. You still have to use net-http directly though! There are other gems of this kind (I’ll address them later) which aren’t part of this list either.
Filtering by these two metrics alone, we come to a much shorter list of candidates, which most rubyists should be familiar with:
- faraday
- excon
- rest-client
- httparty
- httpclient
- typhoeus
- HTTPrb
- mechanize
- httpi
- curb
- em-http-request
- httpx
- net-http
But we can go even further.
Active maintenance
While I don’t personally measure gems by the change rate of the source code, as I believe that there’s a thing such as considering a piece of software as “feature complete”, one can’t apply that line of thought to gems having frequent complaints and bug reports, with barely a response from any maintainer. And there are entries in our remaining list of candidates which, although very popular based on number of downloads and GitHub stars, haven’t been very (if at all) responsive to user feedback in the last couple of years.
Take rest-client for example: one of the oldest and most downloaded gems of the list, its last release was in 2019, with several unanswered bug reports and open pull requests since then.
httpclient, even older that rest-client, is in an even worse condition: last released in 2016(!), several unanswered issues, including this one which is particularly concerning, and should render the gem unusable.
For another example, there’s also typhoeus, last released in 2020, with several open issues as well.
While maintainers shouldn’t be criticized for exercising the freedom of leaving their maintenance duties behind, I find it concerning nonetheless that articles keep popping up recommending their orphaned gems. Consider as well that these gems are still reverse dependencies of thousands of other gems. As an example, typhoeus is the default HTTP client library in openapi-generator, which automates the generation of API client SDKs in several programming languages (including ruby).
So while I’ll probably mention some of them here and there, I won’t further analyse any of the alternatives which are de facto unmaintained.
Wrappers, wrappers everywhere
When it comes to HTTP clients in ruby, there are 3 main groups:
On top of these, you’ll find the “general wrappers” which integrate with as many HTTP “backends” as possible, and aim at providing common interfaces and functionality on top. This group includes faraday, the best-ranked gem by project score in Ruby Toolbox, and httpi, which is a transitive dependency of savon, the most popular ruby SOAP client. This means that, for most of the purposes of this article’s research, they’re irrelevant, although I’ll still include faraday due to its popularity.
Faraday
faraday provides a common HTTP API, and an integration layer every client can integrate with, and distributes common functionality around. In a nutshell, it aims at doing what rack did for application servers: provide a “common middleware” and enable switching the “engine”. Its mirroring of rack’s stragegy goes beyond that, as it even copies some of its quirks, such as the rack env, all the way to “status - headers - body” interface, and the concept of middlewares.
Its approach has had undeniable success: not only the most downloaded, it’s also the HTTP client gem with the most reverse dependencies. Nevertheless, it’s far from the “one true way” of putting HTTP requests in front of people.
For once, it does not guarantee full feature coverage for all supported backends: while one can argue whether this can be made feasible or not, maintenance of the integration layer requires decent knowledge of both faraday and the underlying HTTP client, for each of the supported clients, and there isn’t enough skill around with the time and motivation to do it. So just assume that there’s always something which will be missing for a given integration, some feature which was recently added, some feature which only exist in that particular backend, and so on. Which makes the advantage of possibly switching backends heavily constrained by how deeply the faraday featureset is used.
Moreover, the features it offers (usually via middlewares) often repeat functionality already provided by some of the backends, and sometimes incomplete in comparison. For instance, faraday provides HTTP auth, json encoding, or multipart encoding, as features; however, it only supports Basic HTTP auth (some backends support other schemes authentication schemes, such as Digest HTTP auth). Also, some of the backends already deal with multipart requests (in some cases in a more complete manner, we’ll get to that later), and dealing with JSON may arguably not be a “hard” problem worth having a middleware for (the json standard library makes that already quite easy). Some of the value of these middlewares is therefore a bit dilluted, at least when not dealing with more involved features (like dealing with retries, for instance).
Moreover, by basing itself on the rack protocol, it also inherits its problems. rack API, although simple, ain’t easy. Consider the lowest common denominator:
def call(env)
[200, {}, ["Hello World"]]
end
That env variable isn’t self-explanatory; it’s a bucket of key-value junk. And while the rack spec does a reasonable job of specifying which keys must or should be there and what they should point to, faraday does not provide a specification. So env ends up being an undefined “object which is an hash?”, where you can call things such as env.request, env.ssl, env.body, env[:method]or env[:parallel_manager], and the only way to know which is which, is by reading the code of existing adapters and hope/test you’re using the right thing. All of that for the convenience of having something similar to rack, because it makes things… simple? 🤷
Building features on top of middleware was also a mistake inherited from rack in hindsight. Order matters.
To sum up, although faraday treats the backends it integrates with as dump pipes, they’re rarely dumb. Its choices in integration path also make it rather limiting when building adapters for it, and “spread ownership” from having adapters as its own separate gems (a decision of faraday maintainers) results in adapters covering a “low common denominator” subset of features - which makes it hard to switch adapters - so gems integrating with faraday usually settle with just one. Its user-facing API is reasonably ok (if you forget about parallel requests of multipart support); however, most third-party SDK/gems based on faraday just treat it as an implementation detail, and end up not exposing faraday connections to end users to “augment with middlewares” or even changing backend. And they’ll have to deal with its other quirks. The stripe gem decided not to wait any longer for that upside.
So if you want an HTTP client to implement an SDK on top of, do your research and pick up your own HTTP client, instead of faraday.
Wrapping curl
curl is the most widely used HTTP client in all of software. It’s probably top 10 in most used software in general. It’s used even in Mars. This is synonym to “battle-tested”, “fully-featured”, and “performant”. Being written in C, it’s no wonder that, for a multitude of runtimes with any sort of C ABI interoperability, there are a lot of wrappers for it. And ruby is no exception: typhoeus, curb and patron at least, are all libcurl wrappers, interfacing with it either via libffi or C extensions.
This is no free lunch either. For once, HTTP is only one of the many protocols supported by curl for transfers. The integration will therefore have to make sure that no other protocol can be abused (and, for example, some vulnerable FTP code path is accidentally called), only possible by custom-building curl with support for only HTTP; however, in most cases, integrations will often target the system-installed libcurl, which is open-ended in that regard.
This, on the other hand, makes deployments and dependency tracking harder: now you’ll have to follow changes and security announcements related both to the ruby HTTP library and libcurl. Otherwise, how will you know that a bugfix has been released, or worse, a security fix? (Did I already mention that libcurl is written in C? Here’s a recent reminder.) You’ll also need to ensure that the version of libcurl you want to compile against is installed in your production servers, which makes server setups (containers or not) more cumbersome to maintain: installing curl, or libcurl, is usually something left for the system package manager to handle (aptget, yum, brew…), but these tend to take years to adopt the “latest greatest” version of libcurl, in this case the one containing that security fix you so desperately need. So you’ll have to do the work of downloading, unpacking and installing it as a pre-compiled system package (don’t forget to do the same with the several libcurl dependencies, like libidn2, or nghttp2, etc…). To mitigate some of the pain associated with this, it’s usually best practice that the ruby interface ends up supporting multiple versions of libcurl which may be installed, at the cost of increased risk and maintenance overhead for the gem maintainers.
Alternatively, you can include it as an on-the-fly-compiled vendored C dependency from the gem. That will come with its own can of worms though. Even FFI-based integrations aren’t free of system-related problems. This is the type of overhead that a pure ruby package does not incur.
Usability of the gem API is also a problem. However good libcurl API is, it is idiomatic C, not idiomatic ruby. And for all its efforts in hiding the details of libcurl API, these tend to leak into the surface of end user ruby code:
# using typhoeus
case response.code
when 200
# success
when 0
# special curl code for when something is wrong
# using curb
# curl_easy and curl_multi are C-level libcurl interfaces
# curb exposes them to ruby code almost "as is"
c = Curl::Easy.new("https://http2.akamai.com")
# this is the C-way how conn options are set (this one enables HTTP/2). So one line for each...
c.set(:HTTP_VERSION, Curl::HTTP_2_0)
This could probably be worth it if there’d be a huge feature gap, or the performance was much greater than the non-curl based alternatives, but this is not the case either (more about this later).
So from the standpoint of coding in ruby, I don’t see many advantages which justify the downsides of choosing a library wrapping libcurl.
Wrapping net-http
net-http is the standard library HTTP client. Because it ships with ruby, it’s probably (because I don’t have numbers to back it up, but still, high degree of certainty) the most widely used ruby HTTP client. A significant portion of that usage is indirect though, given how many gems out there wrap it (httparty and rest-client most notably; faraday default adapter is also for net-http).
And that’s because nobody likes writing net-http code. And it’s easy to see why, just look at this cheatsheet: its API is convoluted, verbose, needlessly OO-heavy (why does one need an exception for every HTTP error status code…), it just does not enact joy. Worse, there’s no fix for that: because it’s standard library, and its clunky API is relied up almost as much as ruby core syntax, it’s resistant to change, so its clunkiness is relied upon in a lot of legacy code; any change to address the mentioned points risks having a wide “blast radius” and breaking a significant portion of ruby production deployments.
For this reason, and for a while already, (httparty first release is from 2008!), several libraries have been released with the expressed goal of exposing a user-friendlier DSL for doing HTTP requests, while abstracting the difficulty of dealing with net-http API internally. Off this wave, the “one that parties hard” and rest-client have been the most popular ones. The improvements are perceived by many to offset the drawbacks of the using net-http, while still retaining the whole “engine” intact. This creates a whole new set of problems though.
One is “feature parity drift”. net-http has many features AND lacks key features, but still receives active development, sometimes addresses the latter. For a wrapper, this means that, there’s always going to be a subset of recent functionality which hasn’t been properly wrapped yet. httparty took years to include configuration to cover all possible net-http options: just in 2018, I remember ranting about not being able to enable net-http’s debug output from its API, an option supported in net-http at least since the ruby 1.8.7. days; and somewhere, someone’s still waiting for max_retries support to be added to rest-client.
Another is “implementation multiplication”. net-http lacks some basic core functionality one would expect from an HTTP client, like support for multipart request or digest auth; so faraday has to fill in the gaps, just like faraday, or rest-client, and this despite known patches to net-http itself being developed by the community, all of which is a massive repetition of effort, where certain edge-case bugs may be present in some but not in others, clearly not the most efficient use of a community time and energy.
And meanwhile, new features arrive in net-http every year; it being in standard library, there’s always someone pushing for new features to be added, which reflects in “continuous overhead” for wrapper maintainers, which are required to perpetually shim the new functionality. If the wrappers are maintained at all, that is (rest-client hasn’t since a release in 3 years, so as good as “unmaintained”).
So while I agree with the overall sentiment that net-http is not code I like reading or maintaining, and that its existence only reflects badly on ruby itself (no one will take a “ruby is beautiful” statement seriously by looking at its stdlib HTTP-related code), on the other hand, given the situation I just described, and economy of dependencies trumps freedom of solution choice, using net-http straight up is a better option than sticking with one of its wrappers.
Evaluation
So far, one can see that, although there seems to be plenty of choice, there’s actually a short list one can reasonably hold on to:
- faraday
- excon
rest-client(no release in the last 3 years, high number of unanswered issues)- httparty
httpclient(no release in the last 3 years, high number of unanswered issues)typhoeus(no release in the last 3 years, high number of unanswered issues)- HTTPrb
mechanizehttpi(fringe HTTP client wrapper, no release in almost 2 years)- curb
em-http-request- httpx
- net-http
I’m also removing em-http-request and mechanize from this list. About em-http-request, despite its low-but-existing activity rate, its adoption hangs on it being used via an async framework, eventmachine, which itself hasn’t seen much activity lately, and has fallen out of use and popularity due to its API and runtime incompatibility with “standard” ruby network code. About mechanize, despite it technically being an HTTP client, it’s mostly a “web scraping” tool which interacts with webpages (fill up forms, click links, etc…), impersonating the role of a browser (which is also technically an HTTP client).
So now that we have a defined sample for the analysis, let’s begin.
UX / Developer ergonomics
Response
The most basic feature required from an HTTP client library is performing GET requests (for example, to download a webpage). And that’s a feature that any library mentioned in this article so far (and all the others that haven’t, most probably), is able to easily perform. In fact, it’s so easy, that you can achieve it using similar API for all them:
# please download google front page
uri = "https://www.google.com"
response = HTTPX.get(uri) # httpx
response = Excon.get(uri) # Excon
response = Faraday.get(uri) # faraday
response = HTTP.get(uri) # HTTPrb
response = HTTParty.get(uri) # httparty
response = Curl.get(uri) # curb
response = Net::HTTP.get_response(URI(uri)) # even net-http manages to inline
The response object that each of these calls returns will be a bit “different but similar” in most situations: some will return the response status code via a .status method, while others call it .code:
response.status #=> 200, for httpx, excon, faraday
response.code #=> 200, for HTTPrb, httparty, curb
response.code #=> "200", why, net-http…
The response object will also allow access to the response HTTP headers, in most of cases via a .headers method. The returned object is not always the same, although in most cases is, at the very least, something which allows [key] based lookups, and which can be turned into a Hash:
# httpx
response.headers #=> a custom class, which implements basic [] and []=, responds to .to_h
# excon
response.headers #=> instance of a custom class inheriting from Hash
# faraday
response.headers #=> instance of a custom class inheriting from Hash
# HTTPrb
response.headers #=> a custom class, which implements basic [] and []=, responds to .to_h
# httparty
response.headers #=> a custom SimpleDelegator (to a Hash) class
# curb
response.headers #=> a Hash
# net-http
response.header #=> a custom class, which is HTTPSuccess when 200, something else otherwise….
# all support case-insensitive lookup
response.headers["content-type"] #=> "text/html; charset=ISO-8859-1"
response.headers["Content-Type"] #=> "text/html; charset=ISO-8859-1"
# only httpx provides access to multi-value header
response.headers["set-cookie"] #=> "SOCS=CA…; AEC=AUEFqZe…; __Secure-ENID=12.SE=A8"
response.headers.get("set-cookie") #=> ["SOCS=CA…", "AEC=AUEFqZe…", "__Secure-ENID=12.SE=A8"] , accesses each "set-cookie" response header individually
Finally, the response object allows retrieving the response body, usually via a .body method. As with the example above, the returned object is not always the same, but at the very least can be turned into a String, and in some cases, can be handled as a “file”, i.e. can be read in chunks, which is ideal when dealing with chonky payloads. In some cases, there is custom API for decoding well known encoding formats into plain ruby objects:
# httpx
response.body #=> a custom class
response.to_s #=> a ruby string
response.form #=> if "application/x-www-form-urlencoded" content-type, returns the ruby Hash
response.json #=> if "application/json" content-type, returns the ruby Hash
# excon
response.body #=> a ruby string
# and that's it, no shortcut for decoding
# faraday
response.body #=> a ruby string
# HTTPrb
response.body #=> a custom class, which implements .to_s and .readpartial
# httparty
response.body #=> a ruby string
#faraday
conn = Faraday.new('https://httpbin.org') do |f|
# json decoder supported via faraday middleware
f.response :json
end
json = conn.get("/get").body # already a ruby Hash
# curb
response.body #=> a ruby string
# net-http
response.body #=> a ruby string.
# --------
big_file_url = 'https://some-cdn.com/path/to/file'
# httpx and HTTPrb support chunked response streaming via implementations of .read
# or .readpartial, so this is possible with both:
response = HTTPX.get(big_file_url) # httpx
response = HTTP.get(big_file_url) # HTTPrb
IO.write("/path/to/file", response.body)
# HTTPX has an API just for this:
response.body.copy_to("/path/to/file")
# both also implement .each, which yield chunks
response.body.each { |chunk| handle_chunk(chunk) }
# other options have their own bespoke "read in chunks" callback
# excon
File.open("/path/to/file", "wb") do |f|
streamer = lambda do |chunk, remaining_bytes, total_bytes|
f << chunk
end
Excon.get(big_file_url, :response_block => streamer)
end
# faraday
File.open("/path/to/file", "wb") do |f|
Faraday.get(big_file_url) do |req|
req.options.on_data do |chunk, overall_received_bytes, env|
f << chunk
end
end
end
# httparty
File.open("/path/to/file", "wb") do |f|
HTTParty(big_file_url, stream_body: true) do |fragment|
if fragment.code == 200 # yup, you gotta test fragments….
f << fragment
end
end
end
# curb
File.open("/path/to/file", "wb") do |f|
c = Curl::Easy.new(big_file_url)
c.on_body {|data| f << data}
c.perform
end
# net-http
File.open("/path/to/file", "wb") do |f|
u = URI(big_file_url)
Net::HTTP.start(u.host, u.port) do |http|
request = Net::HTTP::Get.new(u)
http.request(request) do |response|
response.read_body do |chunk|
f << chunk
end
end
end
And this is where the first usability differences are noticeable: 1) httpx and httprb both make the task of dealing with response body chunking a bit more intuitive than the rest, which rely on “same but different” blocks; 2) httpx provides a few shortcuts to parse well-known mime-types into ruby objects (faraday does the same for JSON via some middleware boilerplate); 3) ruby stdlib mitigates some of the shortcomings of other libraries by supporting decoding of common mime types natively (JSON.parse(response.body) for strings works well enough).
Request
Another common feature that all HTTP clients support is requests with other HTTP verbs, such as POST requests. This usually requires support for passing the request body, as well as the setting headers (a feature which is also useful for GET requests btw) in a user-friendly manner.
In order to use another HTTP verb, most libraries will rely on a same-named downcased method, while relying on more or less verbose options to pass extra parameters:
# use-cases:
# 1. GET with the "x-api-token: SECRET" header
# 2. GET with the "?foo=bar" query param in the request URL
# 3. POST the "data" string
# 4. POST the "foo&bar" urlencoded form data
# 5. POST the '{"foo":"bar"}' JSON payload
# 6. POST the '{"foo":"bar"}' JSON payload with the "x-api-token: SECRET" header
get_uri = "https://httpbin.org/get"
post_uri = "https://httpbin.org/post"
# httpx
# 1.
response = HTTPX.get(get_uri, headers: { "x-api-token" => "SECRET" })
# 2.
response = HTTPX.get(get_uri, params: { "foo" => "bar" })
# 3.
response = HTTPX.post(post_uri, body: "data") # defaults to "application/octet-stream" content-type
# 4.
response = HTTPX.post(post_uri, form: { "foo" => "bar" })
# 5.
response = HTTPX.post(post_uri, json: { "foo" => "bar" })
# 6.
response = HTTPX.post(post_uri, headers: { "x-api-token" => "SECRET" }, json: { "foo" => "bar" })
# excon
# 1.
response = Excon.get(get_uri, headers: { "x-api-token" => "SECRET" })
# 2.
response = Excon.get(get_uri, query: { "foo" => "bar" })
# 3.
response = Excon.post(post_uri, body: "data") # does not specify content type
# excon does not provide shortcuts for encoding the request body
# in well known encoding formats, so DIY.
# 4.
response = Excon.post(post_uri, :body => URI.encode_www_form('foo' => 'bar'), :headers => { "Content-Type" => "application/x-www-form-urlencoded" })
# 5.
response = Excon.post(post_uri, :body => JSON.dump('foo' => 'bar'), :headers => { "Content-Type" => "application/json" })
# 6.
response = Excon.post(post_uri, :body => JSON.dump('foo' => 'bar'), :headers => { "Content-Type" => "application/json", "x-api-token" => "SECRET" })
# faraday
# 1.
# starting on the wrong foot, here's a 2nd argument that needs to be nil...
response = Faraday.get(get_uri, nil, { "x-api-token" => "SECRET" })
# 2.
# depending on whether GET or POST, the 3rd argument is either transformed
# into a URL query string or POST form body
response = Faraday.get(get_uri, { "foo" => "bar" }, { "x-api-token" => "SECRET" })
# 3.
response = Faraday.post(post_uri, "data") # defaults to application/x-www-form-urlencoded content-type
# 4.
response = Faraday.post(post_uri, {"foo" => "bar"}) # can encode ruby objects to default
# 5.
conn = Faraday.new('https://httpbin.org') do |f|
# json encoder supported, again via more middleware boilerplate
f.request :json
end
response = conn.post("/post", {"foo" => "bar"})
# 6.
response = conn.post("/post", {"foo" => "bar"}, { "x-api-token" => "SECRET" })
# HTTPrb
# 1.
response = HTTP.headers("x-api-token" => "SECRET").get(get_uri)
# 2.
response = HTTP.get(get_uri, params: { "foo" => "bar" })
# 3.
response = HTTP.post(post_uri, body: "data") # does not specify content type...
# 4.
response = HTTP.post(post_uri, form: {"foo" => "bar"})
# 5.
response = HTTP.post(post_uri, json: {"foo" => "bar"})
# 6.
response = HTTP.headers("x-api-token" => "SECRET").post(post_uri, json: {"foo" => "bar"})
# httparty
# 1.
response = HTTParty.get(get_uri, headers: { "x-api-token" => "SECRET" })
# 2.
response = HTTParty.get(get_uri, query: { "foo" => "bar" })
# 3.
response = HTTParty.post(post_uri, body: "data") # defaults to application/x-www-form-urlencoded content-type
# 4.
response = HTTParty.post(post_uri, body: {"foo" => "bar"}) # can encode ruby objects to default as well
# 5.
# no shortcut provided for json, DIY
response = HTTParty.post(post_uri, body: JSON.dump({"foo" => "bar"}), headers: {"content-type" => "application/json"})
# 6.
response = HTTParty.post(post_uri, body: JSON.dump({"foo" => "bar"}), headers: {"x-api-token" => "SECRET", "content-type" => "application/json"})
# curb
# 1.
response = Curl.get(get_uri) do |http|
http.headers['x-api-token'] = 'x-api-token'
end
# 2.
response = Curl.get(Curl.urlalize(get_uri, {"foo" => "bar"}))
# 3.
response = Curl.post(post_uri, "data") # defaults to application/x-www-form-urlencoded content-type, like curl
# 4.
response = Curl.post(post_uri, {"foo" => "bar"})
# 5.
# needs block-mode to add headers...
response = Curl.post(post_uri, JSON.dump({"foo" => "bar"})) do |http|
http.headers["content-type"] = "application/json"
end
# 6.
response = Curl.post(post_uri, JSON.dump({"foo" => "bar"})) do |http|
# one of these for each new header you'll need to add...
http.headers["content-type"] = "application/json"
http.headers["x-api-token"] = "SECRET"
end
# net-http
get_uri = URI(get_uri)
# 1. and 2.
# net-http does not provide query params API, you have to use URI for that
get_uri.query = URI.www_encode_form({"foo" => "bar"})
# and now you can do the request...
http = Net::HTTP.new(get_uri.host, get_uri.port)
request = Net::HTTP::Get.new(get_uri.request_uri)
request["x-api-token"] = "SECRET"
response = http.request(request)
# 3.
post_uri = URI(post_uri)
response = Net::HTTP.post(post_uri, "data") # defaults to application/x-www-form-urlencoded content-type
# 4.
response = Net::HTTP.post_form(post_uri, {"foo" => "bar"})
# 5.
http = Net::HTTP.new(post_uri.host, post_uri.port)
request = Net::HTTP::Post.new(post_uri.request_uri)
request["content-type"] = "application/json"
request.body = JSON.dump({"foo" => "bar"}
response = http.request(request)
# and let's forget the last, I'm tired of writing net-http examples. you get the picture from the above
This is not exhaustive, but it does tell one a few things: 1) net-http starts showing how verbose can it get; 2) For most options, API shortcuts for encoding the request body are quite limited beyond “x-www-form-urlencoded”; 3) some clients get a bit too creative with the usage of blocks; 4) faraday positional arguments make it a bit confusing to do simple requests. 5) httpx and httprb manage to achieve all examples in concise one-liners; 6) As in the previous section, ruby has quite a lot of stdlib support to circumvent some of these shortcomings (via uri or json bundled gems).
Multipart
Another common and widely supported encoding format for upload files is multipart/form-data, aka Multipart. While a common and old standard, even supported by browsers for form submission, it’s surprising to find that some HTTP clients either don’t implement, require a separate dependency for it, or implement it partially. Let’s demonstrate:
# please:
# 1. POST a "document.jpeg" file
# 2. POST a "selfie.mp4" file
# 3. POST a "document.jpeg" file and a "selfie.mp4" file
# 4. POST a "document.jpeg" file, a "selfie.mp4" file, and a "name=Joe" text field
# 5. POST a "document.jpeg" file, a "selfie.mp4" file, and a "{"name": "Joe", "age": 20}" JSON "data" field
post_uri = "https://httpbin.org/post"
doc_path = "/path/to/document.jpeg"
selfie_path = "/path/to/selfie.mp4"
# httpx
# 1.
HTTPX.post(post_uri, form: { document: File.open(doc_path) })
# multipart payload
# single part with name="document", filename="document.jpg" and content-type=image/jpeg
# 2.
HTTPX.post(post_uri, form: { selfie: Pathname.new(selfie_path) }) # also supports pathnames
# multipart payload
# single part with name="selfie", filename="selfie.mp4" and content-type=video/mp4
# 3.
HTTPX.post(post_uri, form: { document: File.open(doc_path), selfie: File.open(selfie_path) })
# multipart payload
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=video/mp4
# 4.
HTTPX.post(post_uri, form: { document: File.open(doc_path), selfie: File.open(selfie_path), name: "Joe" })
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=video/mp4
# third part with name="name", content-type=text/plain
# 5.
HTTPX.post(post_uri, form: { document: File.open(doc_path), selfie: File.open(selfie_path), data: { content_type: "application/json", body: JSON.dump({name: "Joe", age: 20}) }})
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=video/mp4
# third part with name="data", content-type=application/json
# excon
# does not support multipart requests
# faraday
# does not support multipart requests OOTB
# requires separate faraday-multipart extension gem for that: https://github.com/lostisland/faraday-multipart
require 'faraday'
require 'faraday/multipart'
conn = Faraday.new do |f|
f.request :multipart
end
# 1.
conn.post(post_uri, {document: Faraday::Multipart::FilePart.new(File.open(doc_path), 'image/jpeg') })
# requires using a specific faraday-multipart class for file parts
# mime types need to be known ahead of time!
# 2.
conn.post(post_uri, {selfie: Faraday::Multipart::FilePart.new(File.open(selfie), 'video/mp4') })
# 3.
conn.post(post_uri, {
document: Faraday::Multipart::FilePart.new(File.open(doc_path), 'image/jpeg'),
selfie: Faraday::Multipart::FilePart.new(File.open(selfie), 'video/mp4')
})
# 4.
conn.post(post_uri, {
document: Faraday::Multipart::FilePart.new(File.open(doc_path), 'image/jpeg'),
selfie: Faraday::Multipart::FilePart.new(File.open(selfie), 'video/mp4'),
name: "Joe"
})
# when it comes to text/plain, you can just pass a string
# 5.
conn.post(post_uri, {
document: Faraday::Multipart::FilePart.new(File.open(doc_path), 'image/jpeg'),
selfie: Faraday::Multipart::FilePart.new(File.open(selfie), 'video/mp4'),
data: Faraday::Multipart::ParamPart.new(
JSON.dump({name: "Joe", age: 20}),
'application/json'
)
})
# separate custom part class for other encodings!
# HTTPrb
# does not support multipart OOTB
# requires separate "http/form_data" gem: https://github.com/httprb/form_data
# 1.
HTTP.post(post_uri, form: { document: HTTP::FormData::File.new(doc_path, content_type: "image/jpeg") })
# requires using a specific http/form_data class for file parts
# mime types need to be known ahead of time!
# 2.
HTTP.post(post_uri, form: { selfie: HTTP::FormData::File.new(selfie_path, content_type: "video/mp4") })
# 3.
HTTP.post(post_uri, form: {
document: HTTP::FormData::File.new(doc_path, content_type: "image/jpeg"),
selfie: HTTP::FormData::File.new(selfie_path, content_type: "video/mp4")
})
# 4.
HTTP.post(post_uri, form: {
document: HTTP::FormData::File.new(doc_path, content_type: "image/jpeg"),
selfie: HTTP::FormData::File.new(selfie_path, content_type: "video/mp4"),
name: "Joe"
})
# encodes strings as text/plain
# 5.
HTTP.post(post_uri, form: {
document: HTTP::FormData::File.new(doc_path, content_type: "image/jpeg"),
selfie: HTTP::FormData::File.new(selfie_path, content_type: "video/mp4"),
name: HTTP::FormData::Part.new(JSON.dump({name: "Joe", age: 20}), content_type: 'application/json')
})
# separate custom part class for other encodings!
# httparty
# some built-in multipart capabilities in place
# 1.
HTTParty.post(post_uri, body: { document: File.open(doc_path) })
# multipart payload
# single part with name="document", filename="document.jpg" and content-type=image/jpeg
# 2.
HTTParty.post(post_uri, body: { selfie: File.new(selfie_path) })
# multipart payload
# single part with name="selfie", filename="selfie.mp4" and content-type=application/mp4
# The content-type is wrong!
# 3.
HTTParty.post(post_uri, body: {
document: File.open(doc_path),
selfie: File.open(selfie_path)
})
# multipart payload
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/mp4 (Wrong!)
# 4.
HTTParty.post(post_uri, body: {
document: File.open(doc_path),
selfie: File.open(selfie_path),
name: "Joe"
})
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/mp4 (Wrong!)
# third part with name="name", content-type=text/plain
# 5.
# passing a custom json part is not supported!
# curb
# requires more calls to set it up
# 1.
c = Curl::Easy.new(post_uri)
c.multipart_form_post = true
c.http_post(Curl::PostField.file('document', doc_path))
# multipart payload
# single part with name="document", filename="document.jpg" and content-type=image/jpeg
# 2.
c = Curl::Easy.new(post_uri)
c.multipart_form_post = true
c.http_post(Curl::PostField.file('selfie', selfie_path))
# multipart payload
# single part with name="selfie", filename="selfie.mp4" and content-type=application/octet-stream
# this mime-type is wrong!
# 3.
c = Curl::Easy.new(post_uri)
c.multipart_form_post = true
c.http_post(
Curl::PostField.file('document', doc_path),
Curl::PostField.file('selfie', selfie_path))
# multipart payload
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/octet-stream (Wrong!)
# 4.
c = Curl::Easy.new(post_uri)
c.multipart_form_post = true
c.http_post(
Curl::PostField.file('document', doc_path),
Curl::PostField.file('selfie', selfie_path),
Curl::PostField.content('name', "Joe"))
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/octet-stream (Wrong!)
# third part with name="name", content-type=text/plain
# 5.
c = Curl::Easy.new(post_uri)
c.multipart_form_post = true
c.http_post(
Curl::PostField.file('document', doc_path),
Curl::PostField.file('selfie', selfie_path),
Curl::PostField.content('data', JSON.dump({name: "Joe", age: 20}), "application/json"))
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/octet-stream (Wrong!)
# third part with name="data", content-type=application/json
# net-http
# does not support multipart requests
# you can use the previously mentioned multipart-post gem
# https://github.com/socketry/multipart-post
require "net/http"
require 'net/http/post/multipart'
url = URI.parse(post_uri)
# 1.
File.open(doc_path) do |file|
req = Net::HTTP::Post::Multipart.new(
url.path,
"document" => UploadIO.new(file, "image/jpeg")
)
res = Net::HTTP.start(url.host, url.port, use_ssl: true) do |http|
http.request(req)
end
end
# uses multipart-post provided class to build part
# mime type needs to be known ahead of time!
# 2.
File.open(selfie_path) do |file|
req = Net::HTTP::Post::Multipart.new(
url.path,
"selfie" => UploadIO.new(, "video/mp4")
)
res = Net::HTTP.start(url.host, url.port, use_ssl: true) do |http|
http.request(req)
end
end
# 3.
File.open(doc_path) do |doc_file|
File.open(selfie_path) do |selfie_file|
req = Net::HTTP::Post::Multipart.new(
url.path,
"document" => UploadIO.new(doc_file, "image/jpeg"),
"selfie" => UploadIO.new(selfie_file, "video/mp4")
)
res = Net::HTTP.start(url.host, url.port, use_ssl: true) do |http|
http.request(req)
end
end
end
# 4.
File.open(doc_path) do |doc_file|
File.open(selfie_path) do |selfie_file|
req = Net::HTTP::Post::Multipart.new(
url.path,
"document" => UploadIO.new(doc_file, "image/jpeg"),
"selfie" => UploadIO.new(selfie_file, "video/mp4"),
"name" => "Joe"
)
res = Net::HTTP.start(url.host, url.port, use_ssl: true) do |http|
http.request(req)
end
end
end
# text inputs will be encoded as text/plain
# 5.
File.open(doc_path) do |doc_file|
File.open(selfie_path) do |selfie_file|
req = Net::HTTP::Post::Multipart.new(
url.path,
"document" => UploadIO.new(doc_file, "image/jpeg"),
"selfie" => UploadIO.new(selfie_file, "video/mp4"),
"data" => UploadIO.new(StringIO.new(JSON.dump({name: "Joe", age: 20})), "application/json")
)
res = Net::HTTP.start(url.host, url.port, use_ssl: true) do |http|
http.request(req)
end
end
end
# kinda works....
# first part with name="document", filename="document.jpg" and content-type=image/jpeg
# second part with name="selfie", filename="selfie.mp4" and content-type=application/octet-stream (Wrong!)
# third part with name="data", content-type=application/json...
# but also filename=local.path, which is wrong!!!
As mentioned earlier, multipart encoding support across our researched HTTP clients is quite… non-standardized. excon, faraday, httprb and net-http do not support it “out-of-the-box”, although in the case of the last 3, there are at least well known “extension gems” adding support for it. In some of these cases, the “parts” need to be passed as instances from a custom class (Faraday::Multipart::FilePart for faraday, HTTP::FormData::File for httprb, Curl::PostField for curb, UploadIO for net-http), which make orchestrating these requests needlessly cumbersome, as the ruby File object abstraction they wrap should give them all they need (the ones which require a wrapper class for “non-file” parts are puzzling). Still, by either accepting or wrapping File objects, it indicates that, at best, they probably stream the multipart request payload in chunks (at worst, they may buffer the payload in a file; I didn’t research them that thoroughly).
The feature that is “broken” in most cases is mime type detection; faraday, httprb and net-http extensions pass the “burden” of identifying it to the caller, which now has to figure out how to do it, and orchestrate the whole thing themselves; in other cases (httparty, curb, httpx), this job is outsourced to a separate module or library, but the devil is in the details here: httparty outsources this concern to mini_mime, a “lighter” version of the mime-types gem, which keeps a registry of “file extension to mime types” relations, and as we’ve seen in the snippet above, isn’t accurate for mp4; I don’t know what internally curb uses, but it’s not accurate either for mp4 (perhaps, like typhoeus it integrates with mime-types?).
httpx works by using one of an array of known ruby gems which detect a file’s mime type by inspecting its magic bytes (the most accurate way to figure it out), and if none is available, it’ll use the file command, which requires a shell call, but uses the same approach to detect mime types, and is widely supported and installed. Besides that, it directly supports “low common denominator” interfaces, such as File, Pathname or Tempfile objects, as “parts” (core and stdlib classes), and therefore requires no custom external class to deal with multipart payloads.
Networking
When deploying HTTP clients in production setups, you’ll often find yourself trying to minimize the impact of HTTP requests in your business operations. For instance, you’ll want to make sure that you’re reusing connections when possible, in order to minimize the impact of TCP slow starts, or that very slow peers won’t hog you beyond what you consider reasonable. In short, we’re looking at support for persistent connections, and timeouts.
Most of the bunch support persistent connections (via HTTP/1.1 keep-alive), to some extent, in most of cases using ruby blocks to enable “persistent” contexts to users, and in some cases enabling persistent connection support via a client flag. Some clients will only allow persistent connections to be set on only one peer per block, whether others will enable persistence for all requests within a block. Some will not only allow connection re-use, they’ll also support sending multiple requests at the same time, by leveraging HTTP/1.1 features such as pipelining, or by using HTTP/2 multiplexing.
# please download hackernews first 2 pages
uris = %w[https://news.ycombinator.com/news https://news.ycombinator.com/news?p=2]
# httpx
# using HTTP/2 multiplexing or HTTP/1.1 pipelining, depends of peer server support
responses = HTTPX.get(*uris)
# will make requests concurrently when targetting different peers
responses = HTTPX.get("https://www.google.com", *uris)
# also supports persistent blocks
HTTPX.wrap do |http|
# if you need to do sequential requests and want to reuse the connection
r1 = http.get(uris[0])
r2 = http.get(uris[1])
end
# explicitly setting the client to persistent by default
# will auto-reconnect when peer server disconnects due to inactivity
# will perform TLS session resumption when possible
http = HTTPX.plugin(:persistent) # also sets retries
responses1 = http.get(*uris) # conns open
responses2 = http.get(*uris) #conns still open
http.close # in order to explicitly close connections
# Excon
# persistent connection set for a single peer
connection = Excon.new("https://news.ycombinator.com", :persistent => true)
# sequential connections
connection.get(path: "/news")
connection.get(path: "/news?page=2")
# or send them at once using HTTP/1.1 pipelining (if peer supports)
connection.requests({path: "/news" }, {path: "/news?page=2"})
connection.reset # don't forget to close them when you don't need them anymore
# faraday by itself does not support persistent connections, so you'll have to pick
# adapters which actually support that
conn = Faraday.new(:url => "https://news.ycombinator.com") do |f|
# the net-http-persistenta dapter suports it
f.adapter :net_http_persistent, pool_size: 5
# the httpx adapter does too
f.adapter :httpx, persistent: true
end
# and now you can re-use
response = conn.get("/news")
response = conn.get("/news?page=2")
# faraday also supports a weird parallel api, which only the httpx and typhoeus adapters support, AFAIK
conn = Faraday.new(:url => "https://news.ycombinator.com") do |faraday|
faraday.adapter :httpx
# or
faraday.adapter :typhoeus
end
conn.in_parallel do
response1 = conn.get("/news") # does not block
response2 = conn.get("/news?page=2") # does not block
end # waits until requests are done
response1.body.to_s #=> the response as a ruby String
response2.body.to_s #=> the response as a ruby String
# HTTPrb
# supports persistent connections on a single peer via block:
HTTP.persistent("https://news.ycombinator.com") do |http|
r1 = http.get("/news").to_s
# BIG CAVEAT: because httprb delays consuming the response payload,
# you have to eager-consume it within the block before the next request
# is sent (hence the #to_s calls)
r2 = http.get("/news?page=2").to_s
end
# or initializes the client, and it's up to you when to close
http = HTTP.persistent("https://news.ycombinator.com")
r1 = http.get("/news").to_s # remember to eager load!
r2 = http.get("/news?page=2") # remember to eager load!
http.close # you forgot to eager load! payloads may have been lost!
# httparty does not support persistent connections!
# curb
# supports persistent and parallel requests, also via HTTP/2,
# via the curl multi api ruby shim, which feels like writing C, if you ask me
m = Curl::Multi.new
# add a few easy handles
uris.each do |url|
responses[url] = ""
c = Curl::Easy.new(url) do|curl|
curl.follow_location = true
curl.on_body{|data| responses[url] << data; data.size }
curl.on_success {|easy| puts "success, add more easy handles" }
end
m.add(c)
end
m.perform
# net-http
# supports persistent connection on a single peer via block
Net::HTTP.start("news.ycombinator.com", 443, use_ssl: true) do |http|
# sequential requests only
responses = uris.map do |uri|
req = Net::HTTP::Get.new(URI(uri).request_uri)
http.request(req)
end
end
This example shows httpx versatility in terms of options on how to make persistent, and even concurrent usage of connections, obvious, convenient and flexible. It also starts showing the limitations of the alternatives: the ones that actually support persistent connections, only support it on one peer per connection/session object; while all of them support plain sequential keep-alive requests, only httpx and curb support concurrent requests via HTTP/2 multiplexing and HTTP/1.1 pipelining (excon only supports the latter); while faraday itself does not provide the low level networking features, it does build quite the convoluted API on top of them to support persistent connections and parallel requests; while curb provides access to the low-level features we all expect curl to support, the API to use them feels almost like a verbatim translation from its C API, which is far from “idiomatic ruby”, and does not look like the easiest code to maintain; and oh well, net-http keeps looking verbose and limited (although not as limited as httparty in that regard).
The ability to set timeouts is the other key feature required to mitigate service delivery against service throttling, or network congestion. ruby being so adopted in the startup world, where one sometimes needs to run before it can walk, such matters are usually brushed aside during early product delivery, until production incidents happen. Perhaps given this context, it’s not surprising that it took until 2018 for net-http to introduce a write timeout. But overall, there’s a tendency for ruby HTTP clients to provide timeouts to monitor read/write IO readiness, i.e. “tcp read syscall should not take more than 3 seconds”, instead of a more “cancellation-oriented” approach, “i.e. should receive HTTP response in 3 seconds”. This is a leaky default, as it still exposes clients to slowloris type of situations: if you set 15 seconds read_timeout using net-http, it can still take you minutes to receive a response, if the server sends one byte every 15 seconds. That’s why httpx supports cancellation-type timeouts: write_timeout, read_timeout, and request_timeout options all cover the total time taken to write an HTTP request, receive an HTTP response, or the combination of both, respectively.
Some of the clients will also provide extra timeout options to add similar semantics, but they’re usually incompatible with the defaults, or broken when used alongside other unrelated features.
# please download hackernews main page
uri = "https://news.ycombinator.com/news"
# httpx
# 10 seconds to write the request, 30 seconds to receive the response
# raise `HTTPX::WriteTimeoutError` or `HTTPX::ReadTimeoutError` (both `HTTPX::TimeoutError`)
response = HTTPX.get(uri, timeout: { write_timeout: 10, read_timeout: 30 })
# 3 seconds to fully establish the TLS connection, 40 seconds to send request AND get the response
# raise `HTTPX::ConnectionTimeoutError` or `HTTPX::RequestTimeoutError` (both `HTTPX::TimeoutError`)
response = HTTPX.get(uri, timeout: { connect_timeout: 3, request_timeout: 40 })
# excon
# monitors IO "read" readiness and connection establishment, via `IO.select`
# raises `Excon::Error::Timeout`
response = Excon.get(uri, connect_timeout: 2, read_timeout: 2, write_timeout: 2)
# faraday
# timeout mechanism implemented by adapters
# raises `Faraday::TimeoutError` on error
# requires construction of a connection object
# supports a general timeout for the whole request
conn = Faraday.new("https://news.ycombinator.com", request: { timeout: 5 })
# support granular timeout options
conn = Faraday.new("https://news.ycombinator.com", request: { open_timeout: 5, read_timeout: 2, write_timeout: 2})
response = conn.get("/news")
# but what happens if:
# :timeout is mixed with granular timeouts
conn = Faraday.new("https://news.ycombinator.com", request: { timeout: 2, open_timeout: 5, read_timeout: 2, write_timeout: 2})
# answer: :timeout is ignored.
# timeouts are also set in the adapter
conn = Faraday.new("https://news.ycombinator.com", request: { read_timeout: 2}) do |conn|
conn.adapter :httpx, timeout: { read_timeout: 0.1 }
end
# `HTTPX::ReadTimeoutError` is raised, i.e. you can set timeouts both for faraday and adapter if the adapter allows it!!
# HTTPrb
# monitors IO "read" readiness, via `IO.wait_readable` and `IO.wait_writable` for operation timeouts
# uses Timeout.timeout for TCP/SSL Socket connect timeout
response = HTTP.timeout(connect: 5, write: 2, read: 10).get(uri)
# single timeout for the whole request/response operation
response = HTTP.timeout(10).get(uri)
# meaning a bit unclear in the block form: it is in fact a timeout for the whole block, which goes a bit
# against its "upper bound of how long a request can take" documentation
HTTP.timeout(5).persistent("https://news.ycombinator.com") do |http|
r1 = http.get("/news").to_s
r2 = http.get("/news?page=2").to_s
end
# httparty
# supports the same timeouts as the underlying net-http "engine"
response = HTTParty.get(uri, { open_timeout: 5, read_timeout: 2, write_timeout: 2})
# has a default_timeout, which will be used everywhere in replacement of
# open_timeout, read_timeout and write_timeout, which is a bit confusing.
response = HTTParty.get(uri, { default_timeout: 5 })
# curb
# just uses curl request/response cancellation-based timeout under the hood
# setting a default timeout
Curl::Multi.default_timeout = 5
res = Curl.get(uri) do |http|
# raises exception if request/response not handled within 5 seconds
http.timeout = 5
end
# net-http
# monitors IO "read" readiness, via `IO.wait_readable` and `IO.wait_writable`
# uses Timeout.timeout for TCP/SSL Socket connect timeout
uri = URI(uri)
Net::HTTP.start(uri.host, uri.port, open_timeout: 5, read_timeout: 5, write_timeout: 5) do
# ...
end
To sum up, when in comes to timeouts, there are two libraries, httpx and (in a less granular way) curb, which use a cancellation-oriented mechanism towards a more resilient experience, whereas everything else defaults to readiness-based IO APIs which do not completely protected against slow peers overtaking operations beyond what’s acceptable (which means, you still have to build your own mechanism on top of it). Some of the alternatives try to build a more encompassing timeout on top, but, as in the case of httprb, it results in an inconsistent experience when combined with other features (such as the “persistent” block).
Error handling
In ruby operations, errors can be represented in two ways: a value representing an error, or an exception being raised. HTTP clients may choose one of the two to signal errors in its method calls. For instance, we just talked about timeouts; when a request times out, an HTTP client may raise a “timeout exception” (typhoeus, for example, may use response.code == 0 to signal errors, which is just confusing). Of course, in HTTP requests, not all errors are alike. For instance, 4xx and 5xx response status codes are considered “error responses”, and its up to the client whether to model these as exceptions to be raised, or plain response objects.
Given these options, it’s no wonder that there will be no consensus in how HTTP client handle errors.
uri_ok = "https://httpbin.org/status/200"
uri_404 = "https://httpbin.org/status/404"
uri_timeout = "https://httpbin.org/delay/10"
# httpx
# does not automatically raise exception
http = HTTPX.with(timeout: { request_timeout: 5 })
ok_response, error_response, timeout_response = http.get(uri_ok, uri_404, uri_timeout)
# ok_response is a HTTPX::Response object, with status 200
# error_response is a HTTPX::Response object, with status 404
# timeout_response is a HTTPX::ErrorResponse, wrapping the HTTPX::RequestTimeoutError exception
# .raise_for_status allows for explicit raise
ok_response.raise_for_status #=> 200 response, so does nothing
error_response.raise_for_status #=> raises an HTTPX::HTTPError, which wraps the 404 error response
timeout_response.raise_for_status #=> raises the wrapped exception
# httpx also allows using pattern matching
[ok_response, error_response, timeout_response].each do |response|
case response
in { error: error }
# timeout_response will be here
in { status: 400... }
# error_response will be here
else
# ok_response will be here
end
end
# excon
# returns a plain response for HTTP errors
error_response = Excon.get(uri_404)
error_response.status #=> 404
# raises an exception on timeout
Excon.get(uri_timeout, read_timeout: 5) #=> raises Excon::Error::Timeout
# faraday
# same as excon
error_response = Faraday.get(uri_404)
error_response.status #=> 404
conn = Faraday.new(uri_timeout, request: { read_timeout: 5 })
conn.get #=> raises Faraday::TimeoutError
# HTTPrb
# same as excon
http = HTTP.timeout(read: 5)
error_response = http.get(uri_404)
error_response.status #=> 404
http.get(uri_timeout) #=> raises HTTP::TimeoutError
# httparty
# same as excon, with a twist
error_response = HTTParty.get(uri_404, timeout: 5)
error_response.code #=> 404
# does not wrap errors coming from net-http engine
HTTParty.get(uri_timeout, read_timeout: 5) #=> raises Net::ReadTimeout
# curb
Curl::Multi.default_timeout = 5
error_response = Curl.get(uri_404)
error_response.status #=> "404"
Curl.get(uri_timeout) do |http|
http.timeout = 5
end #=> raises Curl::Err::TimeoutError
# net-http
uri_404 = URI(uri_404)
uri_timeout = URI(uri_timeout)
Net::HTTP.start(uri_404.host, uri_404.port, use_ssl: true) do |http|
request = Net::HTTP::Get.new(uri_404.request_uri)
error_response = http.request(request)
error_response.code #=> "404"
end
Net::HTTP.start(uri_timeout.host, uri_timeout.port, read_timeout: 5, use_ssl: true) do |http|
request = Net::HTTP::Get.new(uri_timeout.request_uri)
http.request(request)
end #=> raises Net::ReadTimeout
From the examples above, one can see that the approach of most HTTP clients is remarkably consistent: HTTP errors result in plain responses, whereas networking errors result in errors under the HTTP client namespace. The outlier is httpx, which returns a (different) response object in both cases, that can be “raised on demand”, and where HTTP and networking errors will result in (different) exceptions. This results in (arguably) better semantics and more options for the end user (at the cost of perhaps breaking rubyists expectations, and at least 1 more instruction in order to get the behaviour of other clients).
Extensibility
This is ruby: even if a library was not designed for extensibility, extending it is still possible; monkey-patching is the last resort.
That being said, it’s still good to rely on libraries with extension capabilities. This usually favours composability and code reuse over controlled contracts, and makes it more difficult to have separate patches stepping on each other, when customizing its usage for one’s needs.
Some of our HTTP clients have supported extensions from the “get go”, and even “dogfood” it by implementing some of its internals using the same contracts. Others supported them only much later, and mostly as an “external” interface. And some of them (like net-http…) just don’t.
httpx comes with a plugin system, which was directly inspired by similar systems found in gems from Jeremy Evans, like roda or sequel; and just like the mentioned examples, most features it provides ship as plugins (which means users don’t pay the cost for features they don’t use). For instance, this is how one enables retries:
http = HTTPX.plugin(:retries)
http.get("https://news.ycombinator.com") # will retry up to 3 times by default
Plugins are essentially modules acting as namespaces for other modules which add functionality to core structures of the library:
module MyPlugin
module ResponseMethods
# adds the method to the response object
def get_server_metric
@headers["x-server-response-time"]
end
end
module ConnectionMethods
def send(request)
start_time = Time.now
request.on(:response) do
puts "this is how much it took: #{Time.now - start_time}"
end
end
end
end
http = HTTPX.plugin(MyPlugin)
resp = http.get("http://internal-domain-with-metrics/this")
puts resp.get_server_metric
httpx plugins are also composable, and a topic in itself.
Alternatively, httpx also provides event-based hooks one can register on the session object:
started = {}
http = HTTPX.on_request_started do |request|
started[request] = Time.now
end.on_response_completed do |request, response|
puts "this is how much it took: #{Time.now - started[request]}"
end.get("http://internal-domain-with-metrics/this")
The difference between both being, event-based hooks are a “high-level” way of intercepting the request/response lifecycle which is easy to learn and use, whereas plugins are more powerful and low-level, but also more involved, and requiring knowledge about httpx internals, to some extent.
excon supports middlewares as extension points, essentially modules defining 2/3 callbacks. It’s relatively simple, and used internally to build features such as following redirects, response decompression, among others. You can define and call it like this:
class MyMiddleware < Excon::Middleware::Base
# can override request_call, response_call and error_call
def response_call(data)
puts data[:headers]["x-server-response-time"]
@stack.response_call(data)
end
end
Excon.get("http://internal-domain-with-metrics/this",
# don't forget to add defaults...
middlewares: Excon.defaults[:middlewares] + [MyMiddleware]
)
Middlewares are called in order. And that has some drawbacks. For instance, a data structure may be changed by one middleware, that will interfere with the execution of the next one. For instance, there’s a middleware to capture cookies, and another to follow redirect responses; If the second is set before the first, it means that cookies won’t be applied to the redirected request. This type of design is more prone to errors.
As mentioned earlier in the article, faraday uses a similar design, inspired from the rack middleware stack:
class Middleware < Faraday::Middleware
def on_request(env)
# do smth with request env
end
def on_complete(env)
puts env[:response_headers]["x-server-response-time"]
end
### or alternatively, you could instead do:
def call(request_env)
@app.call(request_env).on_complete do |response_env|
puts response_env[:response_headers]["x-server-response-time"]
end
end
end
conn = Faraday.new do |conn|
conn.request Middleware # registers #on_request
conn.response Middleware # registers #on_complete
# registers #call
conn.use Middleware
end
Compared to the previous approach, it’s a bit confusing having two ways to accomplish something. And the same drawback applies: order matters. And with that, the inevitable questions follow.
httprb provides a feature called features, which is quite undocumented, albeit used internally to implement de/compression or debug logs. Looking at a few internal examples, the approach is relatively similar to excon’s:
class MyFeature < HTTP::Feature
def wrap_request(request)
# do smth
request # must return
end
def wrap_response(response)
puts response.headers["x-server-response-time"]
response # must return
end
end
# optional: register here
HTTP::Options.register_feature(:my_feature, MyFeature)
http = HTTP.use(MyFeature)
http.get(...)
Being so similar to the examples above, the same drawbacks apply here. And you’ll also have to take into account that, because httprb responses are “lazy”, the wrap_response hook can be called before the response is fully on the client side.
httparty does not provide extension mechanisms like the previous ones. Instead, it promotes its class injection API as a way for users to decorate behaviour around API calls (which is the most popular way of using it):
class Google
include HTTParty
format :html
base_uri 'https://www.google.com'
def q(options = {})
q_query = URI.www_encode_form(options)
self.class.get("/search?#{q_query}")
end
# intercepting all requests, invoke the monkeypatch:
class << self
def perform_request_with_log(*args)
puts "this: #{args}"
perform_request_without_log(*args)
end
alias_method :perform_request_without_log, :perform_request
alias_method :perform_request, :perform_request_with_log
end
end
As the example shows, there are limits to the extensions this approach enables: decorating behaviour is easy, but introspecting the client isn’t a first-class abstraction, and you’ll soon be adding a potentially unhealthy dose of monkey-patching to fill in the gaps.
curb does not support anything of the kind. Either your needs are fulfilled by the wide array of curl features it integrates with, or you’ll have a harder time beating it into shape.
And as for net-http… let’s just say that there are several net-http-$feature gems around, which, at their best, inject APIs into core classes which work in isolation but rarely build well on top of each other, and at their worst, monkey-patch their way in (several tracing / logging / mock libraries do this).
To sum up, and discarding the ones which are not built for extension, most libraries allow extension based on a standard around chained hooks for “sending the request” and “getting a response” (the interpretation of which is library-dependent), and support a more or less friendlier (depending of which example, and personal opinion) API for registering extensions. In most cases, features are provided via these APIs. These extensions cover most of high-level use-cases, but start getting rather limiting for more advanced cases (such as getting information about DNS / socket-handshake / byte-level progress). And that’s where httpx flexible approach to extensions works best, by providing a higher- and low-level way of doing it, and on the latter, by building on a standard which has proven itself with some of the most respected gems within the ruby community.
Performance
The first thing one can say about performance benchmarks, is that you cannot fully trust them. Some of the numbers you’ll see will always be context- or environment-specific: does the gem use a C extension optimized for x86, but that’s not the CPU arch from the machine the benchmark runs on? Is the network IPv4 optimized, thereby penalizing traffic going via IPv6? Are payloads exactly the same?
There are ways to ensure some level of confidence though. First, you must have access to the benchmark code, in order to gain context; you should also have access to the run logs and history; also, benchmarks must run regularly.
Because I didn’t find an acceptable public benchmark which fits these requirements, I went ahead and rolled my own in order to measure the performance difference between some of ruby HTTP clients. While you’re free to inspect it, the gist of it is essentially a pair of containers running in a Gitlab CI pipeline, one with a test HTTP server, and another running the benchmark against it. It runs monthly, so it’s very up-to-date. Local area network ensures negligible network interference in the measurements. There’s a warmup phase, and garbage collection is turned off, ensuring no potential “stop-the-world” interference as well. The benchmark uses the stdlib benchmark gem to measure “real time”, and composes of a series of use-cases (alternatives may not support all of them, hence why not all of them are displayed in all graphs).
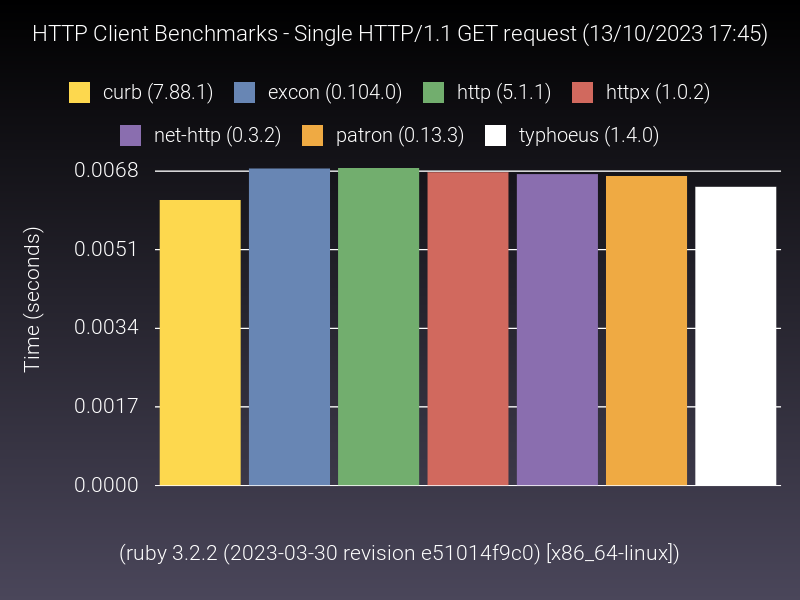
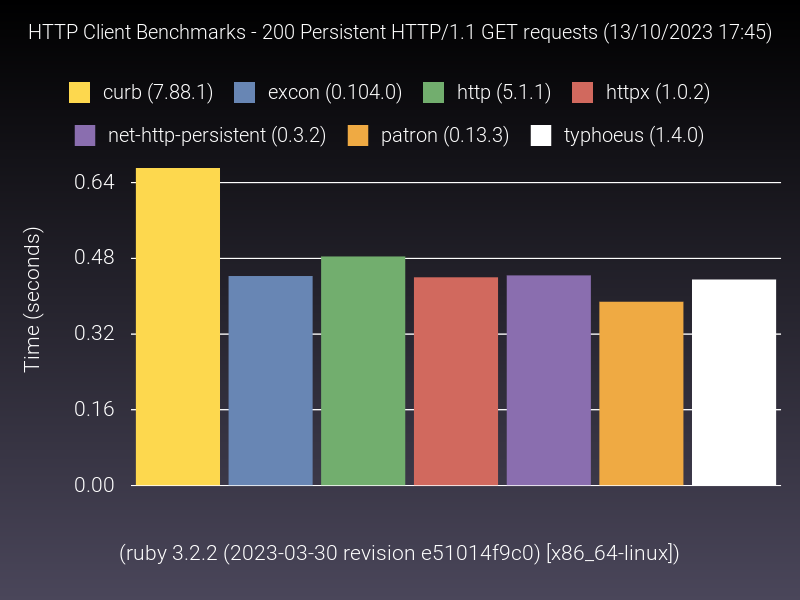
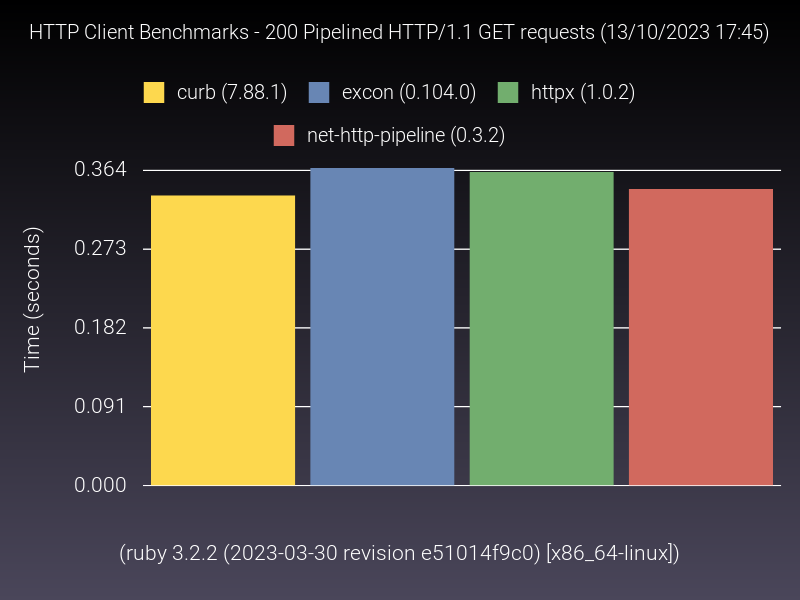
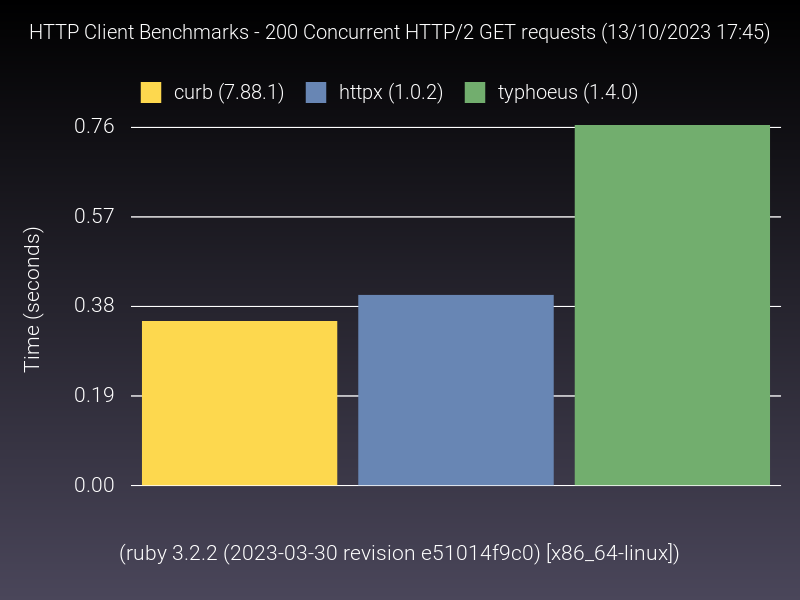
While there could be more use-cases in the benchmarks (feel free to suggest by creating A Merge Request), this shows us that the performance gap between alternatives is not huge, which makes sense: even for such contained scenarios, most time is spent waiting on the network. As httpx maintainer, it’s definitely reassuring seeing it keeping up with the “top of the pack”, particularly when you consider that it is pure ruby (both the HTTP/1 and HTTP/2 parsers are written in ruby), and some of the alternatives claim much better performance due to using C-optimized code, ultimately not delivering (httprb uses the nodeJS HTTP parser via FFI, and used to do it via a C extension; curb and typhoeus use libcurl under the hood as well).
Honorable mention to net-http, which actually shows quite good numbers, which may mitigate a bit some of its UX shortcomings (caveat though: the “pipelined” and “persistent” benchmarks were performed using net-http_pipeline and net-http_persistent gems respectively).
Packaging
With the advent of containers as the ultimate deployment target, the art of setting up VMs has slowly been lost, and shifted into writing recipes, of which dockerfiles are the most popular today. That’s not to say everyone deploys to containers though: there’s also serverless platforms. And “on-premise” never went anywhere either (it’s just under-practised). And what about ruby-based scripting tools (like Homebrew) for your laptop? Don’t forget Windows either: that <2% of the community will chase you in your dreams if they are faced with difficulties. Last resort, you can “write it in JRuby once and run it everywhere”. Bottom line, ruby is everywhere, and when building gems, you best take all this diversity into account, lest you’ll be reminded periodically by someone having troubles with the things you build.
System
So, first thing, how hard it is to install any of our candidates? The options range from “relatively hard”, to “easy”, to “zilch”. Let’s start by the end. net-http is already there. Done. Now that we got that out of the way, we can go to the easy part of the equation: pure ruby gems. Which ones are they? As already mentioned, httpx is pure ruby; the only thing you need to do is use the gem command, or bundler, like you do with any of the other alternatives. excon and httparty are no different: they’re also pure ruby. On the moderate side, you’ll find httprb; it requires the compilation of the llhttp C extension or FFI binding (for the aforementioned nodeJS parser). This means that, in order to install it, you’ll require the whole “C compilation toolchain” including CMake, gcc, and the like. And that includes the deployment environment, as all of them compile-on-install (take that into account in your slim/alpine images). And last of this bunch, you have curb, which not only carries the same requirement of compiling a C extension on install, it also requires a (compatible) installation of libcurl (and bear in mind what was discussed about libcurl-based libs when you need something specific). While not nokogiri-bad in terms of compilation times, its still setup overhead (credit to nokogiri though for adopting pre-compiled binaries, something which none of the extension-dependent libraries researched here does). I’ll omit faraday from the conversation here, as the bulk of the cost lies in the chosen adapter.
Rubygems
# dependency list
httpx
http-2-next
excon
faraday
faraday-net_http
ruby2_keywords
http
addressable
public_suffix
http-cookie
domain_name
unf # C Extensions
http-form_data
llhttp-ffi # C Extensions of FFI
ffi-compiler
httparty
mini_mime
multi_xml
curb # C extensions
net-http
Dependency-wise, the mileage also varies. As mentioned, net-http is all standard library built. excon also ships with no direct dependencies, which is impressive all things considered. httpx ships with one (the http-2-next parser, which is at least maintained by the same person). httparty ships with 2 (why is multi_xml even required? Not sure). faraday has at least 2 (that is, if you do not switch from the default adapter for net-http); httprb has 4 direct dependencies, 8 total. curb has no direct dependencies either (ruby dependencies that is; it does require libcurl).
Is that all necessary? Perhaps, it depends. But I don’t see the point in httprb carrying so much baggage by default: besides the aforementioned parser complication, it also declares http-form_data (same-team maintained, for multipart support), http-cookie, and addressable, aka things that could be optional (ruby already ships with a URI parser), or not loaded by default (I doubt that the majority of its users have used the cookies feature, although everyone seems to be paying the cost). The same could be said of httparty requiring multi_xml (who’s still using XML?). For instance, consider httpx and excon’s approach, where certain features do require the installation of a separate gem, but you only pay the cost if you enable the feature (excon supports addressable as an alternative URI parser, and just to name an example for httpx, the grpc plugin requires the protobuf gem).
Nevertheless, if packaging is the most important variable to consider, you can’t really beat “shipped with ruby”, i.e. net-http.
Features
The feature set that can be built on top of HTTP client is so immense, that it’s impossible to cover in a single blog post (I’d need a book for that, or several). Fortunately, nahi, the former maintainer of httpclient, made my job easier by having built a “common feature matrix” for a presentation he did many years ago in a ruby conference, that I’ll partially use here to highlight the intersection of features across the alternatives covered:
| httpx | excon | faraday | HTTPrb | httparty | curb | net-http | |
|---|---|---|---|---|---|---|---|
| compression | ✅ (also brotli) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Auth | ✅ (basic, digest, ntlm, bearer, aws-sigv4) | ✅ (basic) | ✅ (basic, bearer, token) | ✅ (basic, bearer) | ✅ (basic, digest) | ✅ (basic, digest, gssnegotiate, ntlm) | ✅ (basic) |
| proxy | ✅ (HTTP, HTTPS, Socks4(a)/5, SSH ) | ✅ (HTTP, HTTPS) | 🟠 (adapter-specific) | ✅ (HTTP, HTTPS) | ✅ (HTTP, HTTPS) | ✅ (HTTP, HTTPS, Socks4(a)/5, SSH ) | ✅ (HTTP, HTTPS) |
| proxy auth | ✅ (basic, digest, ntlm) | ❌ | 🟠 (adapter-specific) | ✅ (basic) | ✅ (basic) | ✅ (basic, digest, gssnegotiate, ntlm) | ✅ (basic) |
| cookies | ✅ | ✅ | 🟠 (separate middleware gem) | ✅ | ❌ | ✅ | ❌ |
| follow redirects | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| retries | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| multipart | ✅ | ❌ | ✅ | 🟠 (extra gem) | ✅ | ✅ | ❌ |
| streaming | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| expect-100 | ✅ | ❌ | 🟠 (adapter-specific | ❌ | ✅ | ✅ | ✅ |
| UNIX Sockets | ✅ | ✅ | 🟠 (adapter-specific) | ❌ | ❌ | ✅ | ❌ |
| HTTP/2 | ✅ | ❌ | 🟠 (adapter-specific) | ❌ | ❌ | ✅ | ❌ |
| jruby support | ✅ | ❌ | 🟠 (adapter-specific) | ✅ | ❌ | ❌ | ✅ |
One important thing to take into account is, just because the ✅ is there, it does not necessarily mean that all alternatives implement a feature the same way. For instance, curb support of GSSAPI requires a curl build compiled with gssapi; httprb proxy support does not cover the http_proxy/https_proxy/no_proxy environment variables (which will always come out as surprising if you’re a sysadmin); all of the alternatives, except httpx and curb (via libcurl), implement poor, or simply do not implement, mime type detection of file parts (as already mentioned in the multipart-related section); and as I’ve exposed earlier, the question about streaming response support is not “if”, but “how”.
Still it does show that, when it comes to having the obvious features expected from an HTTP client, the set of alternatives do cover a sufficient chunk not to be considered useless. The only option ticking all the boxes here is httpx, but then again I selected the boxes, so I’d be interested to know whether you think this feature matrix is fair.
Extensions
An HTTP client is not an island. In most cases, it’s a really small from a large program. This program will have certain expectations from some of its dependencies. In the context of an http client, it’ll probably not want to send real requests in test mode. Some metrics / tracing support is usually a must. Can it easily log request information? The answer to these question may make or break the chance of a library being adopted in a given project.
While there’s plenty of tooling available, the ruby community has been settling on a group of dependencies which provide these type of extensions on top of well-known libraries. For instance, there’s webmock or vcr for mocking HTTP requests. Tracing is usually vendor-specific (the datadog SDK, for instance, ships API and shims for well-known libraries in its SDKs), although things are slowly getting a bit more standardized thanks to the Open Telemetry toolchain. And there are several tools for logging HTTP information (of which httplog is one of).
How these libraries choose which HTTP clients to support is up to how standard, or how popular they are, how many users rely on them (and for how long), or how much community “weight” these alternatives command. It’s expected, for instance, that net-http is supported by all of the above (no matter how anti “built-for-extension” it is).
| httpx | excon | faraday | HTTPrb | httparty | curb | net-http | |
|---|---|---|---|---|---|---|---|
| webmock | ✅ | ✅ | 🟠 | ✅ | ✅ | ✅ | ✅ |
| vcr | ❌ | ✅ | ✅ | ❌ | ✅ | ✅ (partially) | ✅ |
| datadog | ✅ | ✅ | ✅ | ✅ | ✅ | 🟠 | ✅ |
| opentelemetry | ❌ | ✅ | ✅ | ✅ | 🟠 | ❌ | ✅ |
| httplog | ❌ | ✅ | 🟠 | ✅ | ✅ | ❌ | ✅ |
This list is not exhaustive, but it does show where more recent alternatives like httpx struggle: joining the group of “well-known” libraries is hard work. Specially when the library was created post-2014, and missed the heyday of when every exciting application in the internet was being built in ruby, and every option was getting a slice of the pie.
What sets httpx apart
So far, the focus of this analysis was to provide perspective, and a wider overview of how well the current well-maintained ruby HTTP clients cover a reasonable set of MUST HAVE and NICE TO HAVE features, enough at least to make this reading enjoyable.
Still, there are things that only httpx does, which you’ll never think about until things don’t work and you need them.
For instance, did you know that httpx is the only pure ruby (excluding curl-based tools here) HTTP client (the only networking library, I think?) that does connection establishment using Happy Eyeballs 2? It will hardly be noticeable to you if production is about “always on IPv4” server-side deployments, or perhaps you don’t care as long as the tool “just works”, no matter whether the tool you’re using gives preference to IPv4 (this is what excon does by the way), until it doesn’t, and then you blame the server. It is certainly a SHOULD HAVE when doing client-side programs on multi-homed networks where connectivity may not be properly set. Such as games, or running bundle install as well (in fact, it’s so important that bundler has its own monkey-patch around TCP connection establishment which half-implements Happy Eyeballs).
It also supports DNS resolution via DoH, a feature so hard to backport to existing networking tools in general, that there are products (such as Cloudflare Zero Trust) which will intercept local UDP/TCP-based DNS traffic through a program installed in your machine, and “translate” them to DoH-based DNS traffic. (curl supports DoH, but curb does not seem to interface with it).
The ability to perform concurrent requests, very useful for scraping scripts for example, is also not to be found often (typhoeus provides something similar, and via a less user-friendly API, as well as curb via Curl::Multi).
It ships a plugin to perform GRPC requests, in case you want to forego the heavy dependency that is the grpc gem (over 100Mb pre-compiled, it can take you Gbs of space if you have to compile it) or are on JRuby. And another supporting WebDAV.
Even something as simple as passing the IP address to use for a given request and which hostname to set in the SNI extension, or in the “Host” header, is practically impossible with any other library, and dead easy with httpx.
Bottom line, while most HTTP clients cover the 70% just fine, and 85% with a few adjustments, httpx works really hard in making the 99% of use-cases accessible.
(Speaking about coverage, httpx publishes how much of the code is covered in CI. Good luck finding numbers for any of the others.)
Conclusion
The main takeaway from this “state of the ruby HTTP clients” is that, no matter whether the “HTTP fringe features” aren’t of your interest, and you’re just interested in covering the 80%, choose a library which is still maintained. If you have a favourite library that wasn’t taken into account in this article, that’s probably why it isn’t here.
Beyond that, the choice will probably be based on prior experience and risk apettite for “trying new toys”, and the requirements you favour the most, which I (hopefully) have outlined and made a good analyis about. Whether it’s API UX, adoption rate, performance or anything else, any of these options will give you some level of acceptable quality.
And when in doubt, use httpx. As it was shown, it stacks well against the competition in any available metric, and is working hard to curb the adoption gap. So help me change that :)