HTTPX 0.19.0 - happy eyeballs, proxy improvements, curl to httpx
26 Jan 2022httpx v0.19.0, the first major (minor version) update of 2022 of the ruby HTTP “swiss-army-knife” client, has just been released. It brings a lot of improvements and bugfixes, as well as a feature that has been a long time coming.
But first, I’d like to share with you my “weekend project”.
curl to httpx
Presenting you the new addition to the httpx website: curl to httpx, a small widget where you can paste a curl command and get the equivalent httpx ruby code snippet.
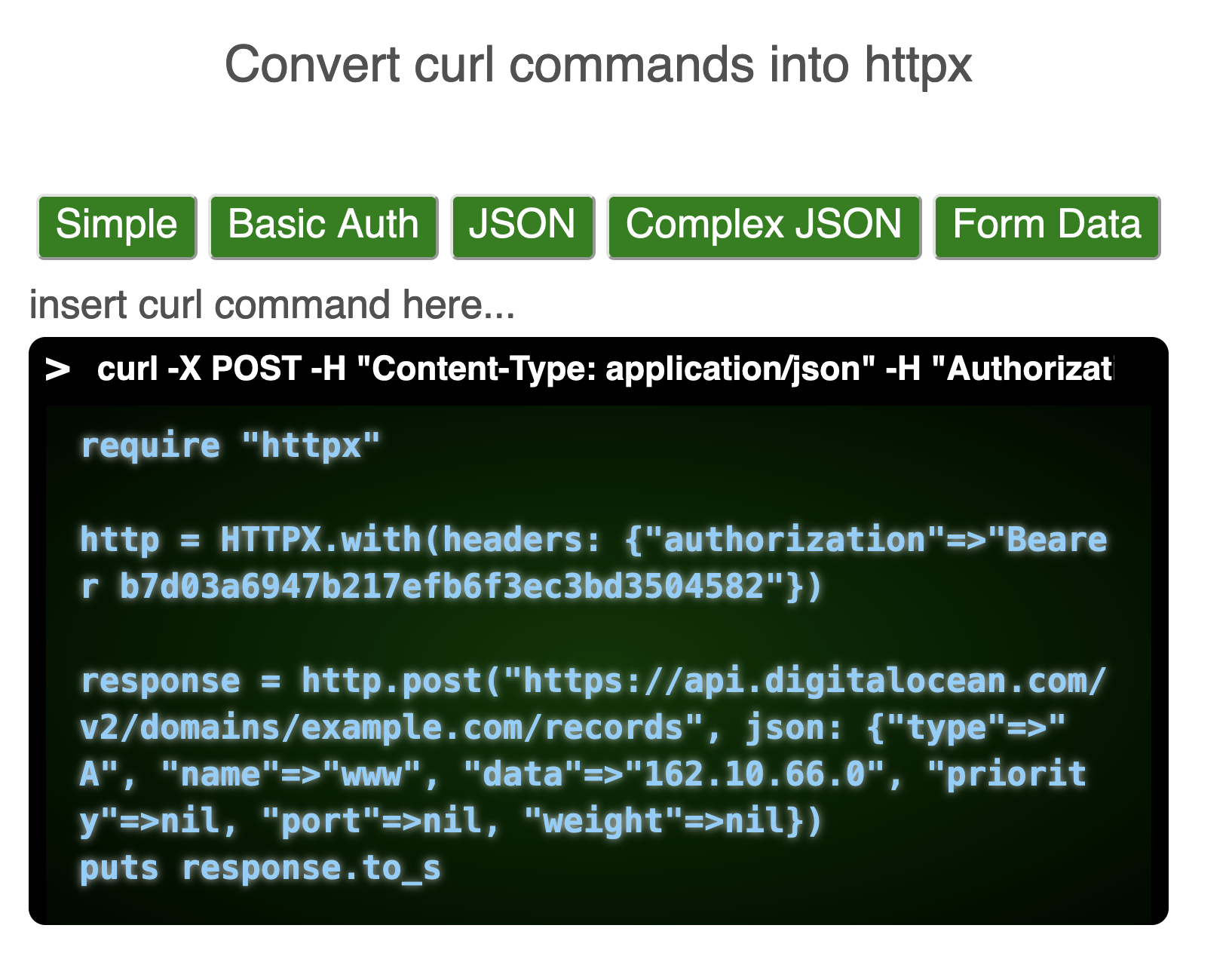
Why?
As the maintainer of httpx, I mostly interact with users via bug reports, and focus on “making it work”. But sometimes, I get to see how others use it, and there’s things to point out usually: users tend to forget error handling (response.raise_for_status), reimplement httpx native features (http.post(url, body: JSON.parse(hash), headers: {"content-type" => "application/json"}) instead of http.post(url, json: hash), handling retries or redirects themselves…), among other things.
Although there’s plenty of documentation (and a wiki), I’m mindful that most users don’t have the time to go through it, and “whatever works first” is a decent success metric. It could be better though. But how?
Turns out I wasn’t the first to think about it. Recently I found curl-to-ruby, a webform which translates curl-based commands (curl is used extensively to query HTTP APIs) into ruby code using the net-http standard library (this webform is itself based on curl-to-go, a similar tool for the go language). I found it pretty cool, because it diminishes the cognitive load (and inevitably going through several net-http cheatsheet and “how-to-make-sense-of-net-http” websites) of using net-http’s terrible API, and still get the benefit of not installing another HTTP client gem.
I’d like to think that httpx API isn’t that terrible, however it’s still a pretty useful tool. So I looked on how to adapt it to use httpx instead. One issue though: curl-to-ruby code is Javascript. I wasn’t excited at the prospect of programming Javascript to generate ruby code.
So I started looking into how to solve this problem using ruby instead.
How?
The first step was to develop a simple script, using stdlib’s optparse, which would “parse” the curl call and paste the ruby script using httpx to standard out. That turned out to be straightforward, even if repetitive (there are >100 curl cli options):
# something like:
require "optparse"
# ...
options = {}
OptionParser.new do |opts|
opts.on("--basic") do # Use HTTP Basic Authentication
options[:auth] = :basic_authentication
options[:auth_method] = :basic_auth
end
opts.on("-F", "--form NAME=CONTENT") do |data|
# ... and so one ...
end
end.parse(curl_command)
puts to_httpx(options)
The second step was to compile it to Javascript that could be used in the website. For that, I used opal, a known “ruby to javascript” compiler.
# the gist of how handling inputs via opal/js
on_txt_change = lambda do |evt|
command = `#{evt}.target.value`
options = {}
urls = parse_options(command, options)
output = to_httpx_output(urls, options)
end
%x{
var input = document.getElementById('curl-command-input');
input.addEventListener('input', on_txt_change, false);
input.addEventListener('change', on_txt_change, false);
}
I may switch to using WASM in the future, now that ruby will support webassembly, but this works well for now.
Then it was a matter of adding the HTML input tags in the jekyll templates, and it was a wrap.
(It took more than a weekend though 😂).
Doing this type of integration using (mostly) ruby felt very enabling. Cheers to the commmunity! Hope you find the widget useful.
Now, back to the v0.19.0 feature announcements.
Happy Eyeballs v2
The main new feature coming in v0.19.0 is Happy Eyeballs support. If you want to know about it in detail you can read the RFC. But the tl;dr is: the DNS layer will request for IPv6 and IPv4 addresses in parallel, and privilege IPv6 connectivity whenever possible (under the conditions defined by the RFC).
Why?
Prior to v0.19.0, httpx would resolve hostnames by first attempting an IPv4 address resolution (DNS A record), and only if the request would fail it’d request for an IPv6 address (DNS AAAA record). In a nutshell, “IPv4 first”.
This decision was taken a long time ago, due to personal experiences with poor quality IPv6-enabled networks, and an assumption that if you target “stable legacy” IPv4 connectivity, I’d have less worries about support.
Yet this always seemed counter-intuitive to httpx mission: it enables seamless HTTP/2, but it gets you stuck with IPv4? That sounds off. Sure, ruby’s mainly used in the cloud, where private networks have been IPv4-only for a long time, but that’s changing.
How?
All of the DNS strategies are using it now. The :native (default, pure ruby) resolver opens 2 sockets, one for each IP family, and uses them for each request; the :https (DoH) resolver uses the same HTTP/2 connection to multiplex both requests; the :system resolver was modified to use getaddrinfo (and doesn’t block anymore), which already does dual-stack under the hood. Caches are also dual-stack aware, as is the hosts resolver.
One thing to note is that both the :native and :https resolver are DNS-based load balancing friendly, whereas the :system resolver is not, due to its reliance on getaddrinfo, which orders IPs before handing them to the caller, thereby changing the order in which they were returned by the DNS server.
Wrap up
There were also plenty of improvements in the proxy layer, and another round of bugfixes. Give it a try!