Context: the missing API in ruby logger
12 Nov 2025Over the last few years, I’ve spent quite a significant chunk of my “dayjob” time working on, and thinking about, observability in general, and logging in particular. After a lot of rewriting and overwriting, “don’t repeat yourself” and coping with ecosystem limitations, I figured it was time to write a blog post on the current state of the art of logging in ruby, what I think it’s missing and what I’m doing about it.
What is logging?
(skip this section if you’re above being lectured about what’s logging again).
Logging is one of those fundamental features of any type of program you use. At a high level, it keeps a record of what a program is and has been doing, be it error messages, or general information, that can be used for audit trail, debugging issues, or generally just figuring out what the hell is happening with a process.
Because this is a feature as old as time, a lot of energy has been spent trying to standardize it. The generally most accepted standard (in UNIX corners at least) has been the Syslog standard, which separates the program generating the message (ex: logging library interface writing to stdout, or a file, or a socket, or all at the same time) from the program managing its storage (ex: logrotate, logstash…) and the program reporting/analysing it (ex: kibana, or plain tail and grep).
(Even) more standards have existed for the message format, which may depend of the type of program you’re using (an example being the common log format for server logs). Some general rules are agreed upon though, such as: there is a log entry per line, a log entry should identify its severity level (examples: “debug”, “info”, “error”, “warn”, “alert”, …), and contain a timestamp, besides the actual log message.
Logging in ruby
The ruby gateway to logging is the logger standard library. In a nutshell, users log by using Logger objects, which know where to write them (internally called “log device”), and how to write them (“formatter”):
require "logger"
# logger which writes messages to standard out
logger = Logger.new(STDOUT)
# writes debug message with the default message format:
#=> $<capital letter for severity level>, [$<timestamp ruby to_s> #$<process id>] $<severity full again, why, we know it already> -- : $<log message>
logger.debug "foo"
#=> D, [2025-11-05T12:10:08.282220 #72227] DEBUG -- : foo
# only writes messages with INFO level or higher
logger.info!
logger.info "foo"
#=> I, [2025-11-05T12:10:54.862196 #72227] INFO -- : foo
logger.debug "foo"
#=>
# use block notation to avoid allocation the message string
logger.debug { "foo" }
#=>
class MyCustomFormatter
# formatters must at least implement this method
def call(severity, time, progname, msg)
"my format -> #{msg}"
end
end
# swap formatter
logger.formatter = MyCustomFormatter.new
logger.info { "foo" }
#=> "my format -> foo"
# enable daily log rotation
daily_logger = Logger.new("my.log", :daily)
daily_logger.info "foo" #=> writes log entry into my.log
# sleep for one day...
daily_logger.info "foo" #=> will rename my.log to my.log.1 and write new message to brand new my.log file
logger is a mixed bag. The default formatter is certainly unusual (although it feels like every programming language has its own default logging format, so perhaps an historical artifact?), and considering ruby’s historical UNIX friendliness, I’m always surprised that default messages do not include the system user. Swapping the formatter is easy though.
The Log device interface feels a bit more limiting. While writing to stdout/stderr or a file is easy, writing to a socket (like a syslog server) is much harder than it needs to be (you have to write your own Logger::LogDevice subclass). It also works a bit counter to the Syslog standard described above, as, being a utility to “streamline the generation of messages”, it shouldn’t really care about storing details (such as log rotation), and doesn’t support the ability to write to multiple locations at once.
Still, it’s rather straightforward to use, as long as none of the limitations mentioned above matter to you.
Logging in rack
One of the main uses of ruby in the industry has been web applications. Most of them are wrapped inside rack containers and deployed using application servers like webrick or puma. rack ships with a common logger middleware, which emits a log entry per request using the apache common logging format:
# example of a web request log:
# client ip, user or "-", datetime, method, path, http version, status code, response body size in bytes, processing-to-send time
#
127.0.0.1 - [01/May/2025:07:20:10 +0000] "GET /index.html HTTP/1.1" 200 9481 10
you can use it in your rack application by adding it to your config.ru file:
# config.ru
use Rack::CommonLogger
run MyApp
The above isn’t common though, as the framework you may be using to build your application may do it for you, or ship with its own logger middleware implementation. For instance, both roda and sinatra ship or recommend its own extension plugin, for different reasons, such as performance or configurability.
Logging in rails
In rails applications, most interact with logging via the Rails.logger singleton object. While mostly API compatible with the standard logger library counterpart, it bundles its own (rails) conventions on top of it.
Like a true schroedinger’s cat, Rails.logger is and is not a logger at the same time: the documentation says it’s an instance of ActiveSupport::Logger (a subclass of stdlib’s Logger), but if you inspect it in the console, it’s actually something else:
Rails.logger #=> instance of ActiveSupport::BroadcastLogger
Rails documents that one can change the logger in application config (a common use case is to write test logs to /dev/null by setting config.logger = Logger.new("/dev/null")) in config/environments/test.rb), but in the end, the singleton instance is an instance of ActiveSupport::BroadcastLogger, a proxy object which can register multiple log devices and forward message calls to them. From the official docs:
stdout_logger = Logger.new(STDOUT)
file_logger = Logger.new("development.log")
broadcast = BroadcastLogger.new(stdout_logger, file_logger)
broadcast.info("Hello world!") # Writes the log to STDOUT and the development.log file.
It seems that the broadcast logger was rails internal solution to the lack of support for multiple log devices per Logger instance in the logger standard library.
The rails logger also ships with its own formatter, which does the simplest possible thing:
Rails.logger "foo" #=> "foo"
Alternatively to ActiveSupport::Logger, rails has ActiveSupport::TaggedLogging. This adds the capability to add “context tags” to a scope, where all log messages within it will be formatted with it:
logger = ActiveSupport::TaggedLogging.new(Logger.new(STDOUT))
logger.tagged("FOO") { logger.info "Stuff" } #=> Logs "[FOO] Stuff"
logger.tagged("BAR") do
logger.info "Stuff" #=> Logs "[BAR] Stuff"
end
logger.tagged("FOO", "BAR") { logger.info "Stuff" } #=> Logs "[FOO] [BAR] Stuff"
Structured logging
All those standards and message formats are nice and all, but in 2025, everyone and their mothers want structured logging. The most common format, at least in the corners I work in, is JSON. It probably has to do with it, in spite of its deficiencies, being a quite simple serialization format and widely adopted, which guarantees virtually universal support. As a counterpart to the log management stack for syslog-type systems, new stacks started popping up, such as the fluentd/logstash/elasticsearch/kibana OS stack, alongside SaaS solutions like Splunk or Datadog.
There was renewed interest in re-standardizing log message “envelopes”, one of the emerging standards being the logstash event format.
# logstash event format
'{"message":"foo","tags":["tag1"],"source":"127.0.0.1","@version":"1","@timestamp"}'
That being said though, the ecosystem hasn’t really consolidated on formats yet, so it’s common to see different standards in use across different systems. What’s common across all of them though, is the need to logically structure the log message separately from its associated metadata, or context.
Nowadays, structured logging fills a complementary role in the larger picture of observability.
The new world of observability
Monitoring the health of a system isn’t a new requirement. As mentioned above, logging is quite an old OS telemetry feature. Back in the “old days” of server/system administration, it was common to set up software like Nagios to collect OS-level telemetry data and visualize i.e. memory consumption, CPU usage, instance connectivity, among other data points. in user-friendly web GUIs.
Since the explosion of Cloud Computing and the Google SRE playbook, and trends such as microservices or lambda functions, observability took a center stage and grew until it incorporated several concepts which used to be thought of as apart from each other. Nowadays the buzzwords are RUM, Open Telemetry, APM, RED metrics, error tracking, among others, and these are all driven by system and application-emitted metrics, logs, and its new more recent friend, traces, which are a way to visualize execution flows which incorporate related execution flows (usually callend “spans”) within it, as horizontal bars correlating timelines.
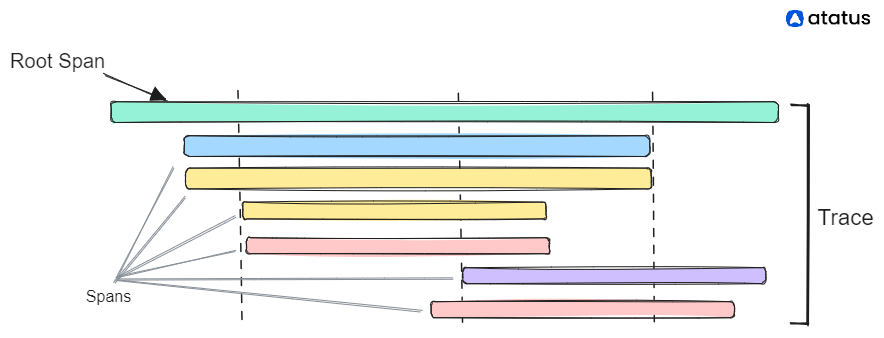
That center stage translated into big business, and companies like Datadog, Sentry or Honeycomb became almost as critical to a client’s success as the features that client provides. Observing, measuring, monitoring the health / performance / volume of our applications has never been as easy (and as expensive).
ruby logging in 2025
Sadly, the ruby logger library APIs didn’t keep up with the times, and are quite limited for this new paradigm. While nothing stops anyone from swapping the default formatter with a JSON capable counterpart, the Logger::Formatter API, which relies on implementation of call with a fixed set of positional arguments, makes it impossible to support metadata other than what the function already expects:
class MyJSONFormatter
# formatters must at least implement this method
def call(severity, time, progname, msg)
# can't receive i.e. user data, just the 4 levels above:
{ severity: time: progname:, message: msg }.to_json
end
end
This diminishes its reusability, and as a result, every other logger library in the ecosystem which logs JSON (and other formats) does not use the logger library as its foundation layer, and ends up reinventing the Formatter API to its needs.
But don’t take my word for it. Looking at the most used logging libraries in ruby toolbox which support structured JSON format, log4r has its own base formatter class which defined #format(String event) as the overridable method; lograge also has its own base formatter class which defines #call(Hash data) as its own, while semantic logger also has one, this time defining #call(SemanticLogger::Log log, SemanticLogger::Formatters::Base logger), and so does logstash-logger have its own base formatter, which funnily enough supports… the same call API as ruby logger formatters!
This is official xkcd territory.
(Practically all of the above also solve the problem of writing to multiple log devices, in most cases naming this feature “log appenders”. But this is not the feature I’m writing the post about).
rails logging in 2025
Given that ActiveSupport::Logger is a subclass of Logger, it also inherits (OO-pun intended) its problems, therefore by the transitive property, rails logger does not support structured logging (and JSON in particular). So if your rails application emits JSON logs, you’re either using one of the alternatives above, or an in-house library made out of spare parts of everything mentioned so far, or worse (gulp) a parser (like grok) regex-matching your string entry and spitting a JSON from it.
The most stable, and to my knowledge, more widely adopted logging libraries, are lograge and (rails) semantic logger.
In both cases, the Rails.logger singleton instance broadcasts to a custom logger implementation provided by the library, and the main log-related subscriptions for default notifications in-and-around business operations (like processing web requests) are swapped by custom (to each library) subscriptions, which make use of the logger API and allow adding extra context to each of these log messages.
lograge
lograge documents a custom_options callback, which receives a hash and returns another hash. The received hash is the event hash which gets passed to request-level event notifications, and can be augmented in controllers by re-defining the controller append_info_to_payload callback. The returned hash gets passed “as is” to the eventual JSON log entry (which also contains a readable “message”), giving almost full control of the JSON message format.
It has several drawbacks though, one of them being, it only subscribes to action-controller-level events, so active jobs will keep being logged by “standard” rails logger. Also, it’s not possible to share or add different context to other logger calls when using Rails.logger.info and friends.
If you’re using the rails framework for anything other than web requests, I wouldn’t recommend it.
(It also subscribes to action cable events, but I suspect very few applications running in production use it).
semantic logger
In turn, (rails) semantic logger subscribes not only to action controller events, but active job events as well (and active record events, and active view, and action mailer… if that can be subscribed, it will be subscribed!), which makes it more compelling to use. It also ships with interesting features which allow to not only add context to direct logging calls, but setting context to a given scope as well:
logger.info("hi", payload: {"foo" => "bar"})
#=> '{"message":"hi","payload":{"foo":"bar"}....'
logger.info("hi")
#=> '{"message":"hi",....'
SemanticLogger.tagged("foo" => "bar") do
logger.info("hi")
#=> '{"message":"hi","payload":{"foo":"bar"}....'
end
logger.info("hi")
#=> '{"message":"hi",....'
Still, while having this feature, semantic logger still disappoints by recommending a similar type of integration as lograge does for requests (log_tags callback + append_info_to_payload), which limit the scope of request-level payload to the single logger call happening within log subscribers. It feels like a lost opportunity, considering that it’d be great to share that context with all user-defined logger calls happening within the scope of the request processing (including calls happening from within the controller action), and other rails-level business transactions (such as active job #perform calls) do not have an append_info_to_payload counterpart (perhaps someone should suggest that feature to rails?).
The resulting JSON format (all non-standard context under "payload", some things under "named_tags" when using some obscure API) isn’t the friendliest either, and in most cases, ends up being rewritten by a pre-processing step before log ingestion happens.
Still, despite all its flaws and somewhat clunky API, it showcases the potential of, for lack of a better name, a logger context API.
Context API
Imagine if, during the scope of request processing, several context scopes could be interleaved, each one with its context, tearing down each sub-context when exiting blocks; this context could then be used in the log analysis engine to aggregate groups of messages tags from each particular context, allowing more fine-grained filtering.
If you’re using any type of tracing integration, you don’t need to imagine, because this is how the tracing API works! For example, if you are using the datadog SDK:
# from the datadog sdk docs:
def index
# Get the active span and set customer_id -> 254889
Datadog::Tracing.active_span&.set_tag('customer.id', params.permit([:customer_id]))
# create child span, add tags to it
Datadog::Tracing.trace('web.request') do |span|
span.set_tag('http.url', request.path)
span.set_tag('<TAG_KEY>', '<TAG_VALUE>')
# execute something here ...
end
end
Something like this, using plain loggers, should be possible too:
def index
logger.add_context(customer_id: params.permit([:customer_id]))
# logger.info calls will include the "customer_id" field
logger.with_context(http_url: request.path, tag_key: "tag_value") do
# logger.info calls will include the "customer_id", "http_url" and "tag_key" fields
end
# logger.info calls will only include the "customer_id" field
end
And that’s why, to somewhat stitch the inconsistencies described above together, I’m proposing such an API to the logger standard library.
Feature Request
For a more detailed description, you can read the issue and PR description/comments. In a nutshell, two ways are introduced of adding context: per block (via Logger#with_context) and per call (keyword argument in Logger#info, Logger.error and friends):
# per block
logger.with_context(a: 1) do
logger.info("foo") #=> I, [a=1] [2025-08-13T15:00:03.830782 #5374] INFO -- : foo
end
logger.with_context(a: 1) do
logger.with_context(b: 2) do
logger.info("foo") #=> I, [a=1] [b=2] [2025-08-13T15:00:03.830782 #5374] INFO -- : foo
end
end
# per call
logger.info("foo", context: {user_id: 1}) #=> I, [user_id=1] [2025-08-13T15:00:03.830782 #5374] INFO -- : foo
logger.info(context: {user_id: 1}) { "foo" } #=> I, [user_id=1] [2025-08-13T15:00:03.830782 #5374] INFO -- : foo
The proposal tries to retrofit context into the current default message format, and does not aim at proposing a JSON message formatter. At least until this is done.
That’s it!
There’s a lot of devil in the details though, and if you’ll read through the PR discussions, there were many meaningful points raised:
- how/where to manage contexts?
- ruby should manage contexts per thread AND per fiber, which raises some questions around context sharing across parent-child fibers, what the runtime supports OOTB, as well as certain core APIs which spawn fibers under the hood.
- should context be managed in formatters rather than logger instances?
- I’m leaning on the latter, but it’ll depend on future developments in
logger. For example, will it ever support multiple log devices per instance? And if so, will each log device have its own formatter? In such a case, should context be shared across formatters?
- I’m leaning on the latter, but it’ll depend on future developments in
- what’s the bare minimym feature set
- do we need per-call context? can it get away with
with_contextonly?
- do we need per-call context? can it get away with
Logging context in rack
Unlocking per-request logging context becomes as simple as including this middleware in your rack application:
class LoggingContext
def initialize(app, logger = nil)
@app = app
@logger = logger
end
def call(env)
@logger.with_context { @app.call(env) }
end
end
# then in config.ru
use LoggingContext
run MyApp
You could then make use of this API in your application, knowing that context will be correctly tore down at the end of the request lifecycle:
# This is just an example of how to add request info as logging context, it is NOT supposed to be a recommendation about how to log
# authentication info.
# roda (with rodauth) endpoint
class MyApp < Roda
plugin :common_logger
plugin :rodauth
# ...
route do |r|
logger = @logger || request.get_header(RACK_ERRORS)
r.rodauth
get 'index' do
@user = DB[:accounts].where(:id=>rodauth.session_value).get(:email)
logger.with_context(user: { id: @user.id }) do
view 'index'
end
end
end
end
# rails controller action
class MyController
before_action :require_user
around_context :add_logging_context
# ...
def index
Rails.logger.info "about to index" # will log user.id in context
end
private
def add_logging_context
Rails.logger.with_context(user: { id: @user.id }) { yield }
end
end
Logging context in background jobs
Similar approaches can be applied for your preferred background job framework. For brevity, I’ll just show below how you could use the same callback/middleware strategy for Sidekiq and Active Job:
# 1. Sidekiq
class LoggingContext
include Sidekiq::ServerMiddleware
def initialize(logger)
@logger = logger
end
def call(job, payload, queue)
@logger.with_context(job: { queue: queue, id: job["jid"] }) { yield }
end
end
# when initializing...
Sidekiq.configure_server do |config|
config.server_middleware do |chain|
# if you're using rails, replace bellow with Rails.logger
chain.add MyMiddleware::Server::ErrorLogger, logger: LOGGER
end
end
# then in job...
class MyJob
include Sidekiq::Job
def perform(arg1, arg2)
LOGGER.info "performing" # will include job.queue and job.id in context
end
end
# 2. Active Job
class ApplicationJob < ActiveJob::Base
around_perform do |job, block|
Rails.logger.with_context(job: { queue: job.queue_name, id: job.id }) do
block.call
end
end
end
# then in job...
class MyJob < ApplicationJob
def perform(arg1, arg2)
Rails.logger.info "performing" # will include job.queue and job.id in context
end
end
Logging context in other languages
Another angle of this discussion is looking at how other ecosystems solve this problem. I’ll just mention a few examples, as my purpose is not to be exhaustive, so apologies in advance if I skipped your second-preferred language.
Java
While core Java Logger APIs do not seem to support this, most applications use the log4j library, which supports a feature called Thread Context, which is very similar to the one described above:
ThreadContext.put("ipAddress", request.getRemoteAddr());
ThreadContext.put("hostName", request.getServerName());
ThreadContext.put("loginId", session.getAttribute("loginId"));
void performWork() {
// explicitly add context for this function, which copies all context until then
ThreadContext.push("performWork()");
LOGGER.debug("Performing work"); // will include ipAddress, etc...
// do work
ThreadContext.pop();
}
// or with auto-closing enabled
try (CloseableThreadContext.Instance ignored = CloseableThreadContext
.put("ipAddress", request.getRemoteAddr())
.push("performWork()")) {
LOGGER.debug("Performing work");
// do work
}
Verbose (it’s Java), but it works!
Java 21 released Virtual Threads, which are somewhat like coroutines which coordinate execution across a number of OS threads. It’s not clear to me whether log4j thread contexts support them OOTB.
go
One of go’s main features is the wide array of functionality provided by its standard library, and logging context is no exception.
The standard library logging package is called slog, which supports, in the usual go way, using context.Context objects to pass structured context, but also extending logger instances themselves, via the .With call, with per instance context:
(slog also ships with a JSON formatter.)
import (
"context"
"log/slog"
"os"
)
func main() {
logger := slog.New(slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{
Level: slog.LevelInfo,
}))
// Add default attributes to all log entries
baseLogger := logger.With(
"app", "example",
"env", "production",
)
slog.SetDefault(logger)
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// Extract or generate a request ID for tracing
requestID := r.Header.Get("X-Request-ID")
if requestID == "" {
requestID = "default-id"
}
// Attach the request ID to context
ctx := context.WithValue(r.Context(), "request_id", requestID)
// Create request-scoped logger
reqLogger := logger.With(
"request_id", requestID,
"path", r.URL.Path,
"method", r.Method,
)
handleRequest(ctx, reqLogger, w, r)
}
http.ListenAndServe(":8080", nil)
}
func handleRequest(ctx context.Context, logger *slog.Logger, w http.ResponseWriter, r *http.Request) {
logger.InfoContext(ctx, "Handling request") // includes request_id, path, metho
w.Write([]byte("Request handled"))
logger.InfoContext(ctx, "Request processed") // includes request_id, path, metho
}
While it takes some getting used to both ways of doing the same thing, it’s still interesting to see how the usage of explicit context forwarding permeates across the ecosystem, including in logging.
python
As usual with all things python, it’s all a bit of a mess, and in accordance with the “there’s always one obvious way to do something” reality, there are at least 2 ways of doing it.
BFirst, when using the standard logging package, per-call context is supported via the extra keyword argument:
logger = logging.getLogger()
logger.info("msg", extra={"foo": "bar"})
Internally, logging message calls will generate Log records, an object which contains multiple attributes, including this .extra; these records then get passed to formatters, which will access this extra context when formatting the message.
Now that we got that out of the way…
The logging package avoids extra API to support contexts, instead providing ways for an introspection-based approach, such as the logging.LoggerAdapter interface.
import logging
from flask import g
class UserAdapter(logging.LoggerAdapter):
def process(self, msg, kwargs):
extra = kwargs.get("extra", {})
extra['user_id'] = g.user_id
kwargs['extra'] = extra
return msg, kwargs
logger = logging.getLogger(__name__)
adapter = UserAdapter(logger)
The adapter above relies on importing external context store APIs, which tend to be framework-specific; for once, the example above will only work with flask, so you may have troubles reusing this outside of it, such as, p. ex. a background task execution lifecycle (something like celery, for example). If the background task framework supports a similar imported context store API based approach, in order to reuse the adapter you’ll still have to play a game of “which execution context am I in?”. All in all, you’ll have a hard time if you want to use that local variable as context transparently on multiple log calls.
Some of these limitations can be circumvented by using the contextvars package.
Another recommendation to add contextual info is to using logging.Filter:
import logging
from flask import g
class UserFilter(logging.Filter):
def filter(self, record):
record.user_id = g.user_id
return True
# later, you'll have to explicitly add the filter to the logger
logger = logging.getLogger(__name__)
f = UserFilter()
logger.addFilter(f)
Adding this to all (or a subset of) endpoints of a web application will involve a similar middleware such as what loggerAdapter provides, while having the same limitations, so I’m not sure what this abstraction buys one, besides making it a bit more explicit in some cases.
All in all, python’s approach(es) does not feel at all ergonomic, requiring boilerplate to get things done. It is truly the most low-level of high-level languages.
Beyond logging
If the feature gets accepted, most of the inconsistencies described above can be dealt with. For once, all base formatters from the libraries described above can base off the standard library Logger::Formatter, thereby standardizing on a single API and enabling reusable extensions. Adding a simpler json formatter variant will be much easier (who knows, perhaps the standard library can ship with one). rack could ship with a logging context middleware.
It also opens up quite a few opportunities for context coalescing.
For instance, logs/traces/metrics context sharing. Imagine tools like the datadog SDK, or its OTel counterpart. what if, instead of adding tags to traces only, one could add it automatically to the context of a known logger instance?
Datadog.active_logger = Rails.logger
# add as context to current active trace and log
Datadog.active_trace.set_tags("foo", "bar")
# instead of the current version, which only adds to active trace
Datadog::Tracing.active_trace.set_tags("foo", "bar")
The datadog dashboard already links traces with logs which contain a corresponding “trace_id” field. Now imagine not having to deal with the mental burden of knowing which tags are searchable in APM trace search, which ones are searchable for logs, which ones are common which ones are similar… there’d be a single context to deal with! (Now, if only datadog could listen to their users and import user-defined trace tags to trace-generated metrics…).
This could be the rug that ties the whole room together.
Rails 8 new event subscription API
If you mostly use ruby through the lens of rails, you may have looked at the recent 8.1 announcement and read about Structured Event Reporting, and may be thinking “that solves it, right?”.
Sorta, kinda, and no.
It sorta solves the problem around sending context into events. Above I complained about the append_info_to_payload being the only way to arbitrarily inject data into the event object, and this only working for the web request case. So this is a +1.
It kinda makes it work for “rails logs”, as event subscription is how rails default request/view/activerecord logs are emitted. This is probably why most of the API around Rails.event mimics some of the Rails.logger API (#tagged being the most obvious one), and hint at it being the main motivating factor behind the feature (it was developed by a Shopify employee, so you’d have to confirm with someone who works there).
But ultimately, it does not solve the main issue around logging context. Rails.logger is public API. As application users, we are encouraged to use it as the gateway to write our own logs. Event subscription is nice, but I’m not going to pivot to “emit events so I can write logs”. So while nice, it looks a bit like a rails solution to a rails problem.
What now?
This does not solve the lack of support for multiple log devices. Nor support for non-file log devices. Those are its own battles. If you feel strongly about any of them though, don’t hesitate, go ahead and propose a solution.